Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) Read More →
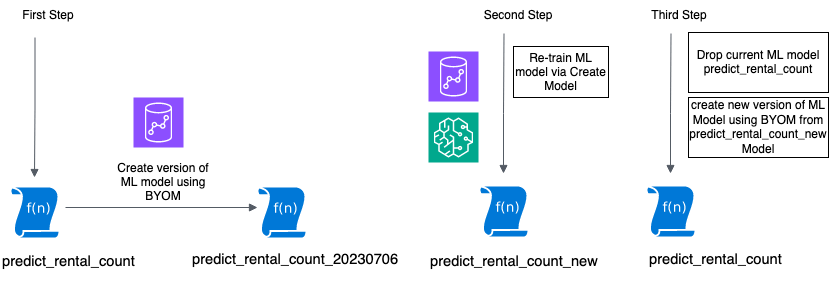
Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) Read More →
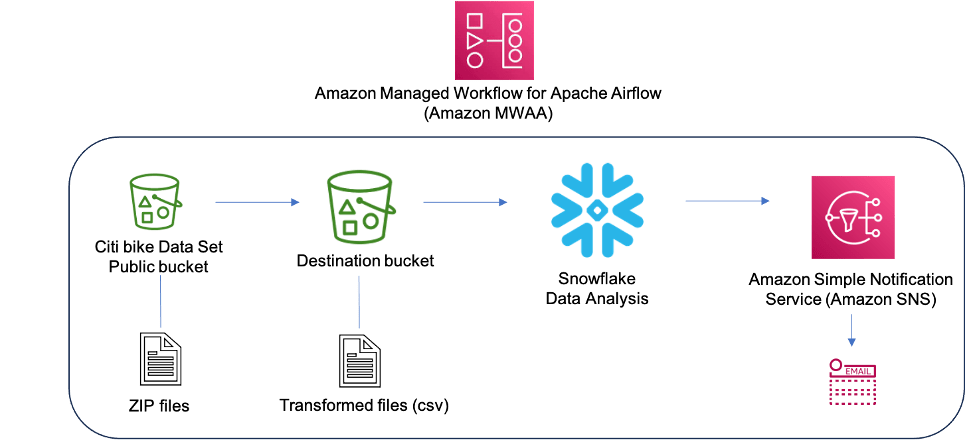
This blog post is co-written with James Sun from Snowflake. Customers rely on data from Read More →
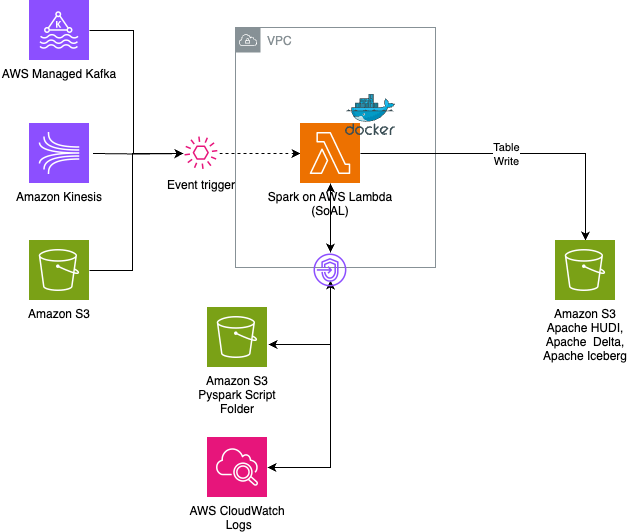
Spark on AWS Lambda (SoAL) is a framework that runs Apache Spark workloads on AWS Read More →
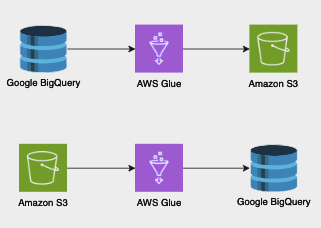
Data integration is the foundation of robust data analytics. It encompasses the discovery, preparation, and Read More →
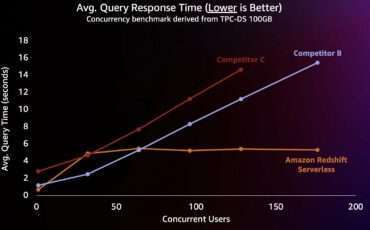
Like virtually all customers, you want to spend as little as possible while getting the Read More →
Software upgrades bring new features and better performance, and keep you current with the software Read More →
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers Read More →
As the scale and complexity of microservices and distributed applications continues to expand, customers are Read More →
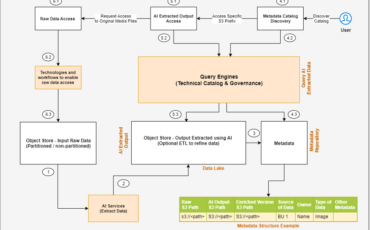
Unstructured data is information that doesn’t conform to a predefined schema or isn’t organized according Read More →
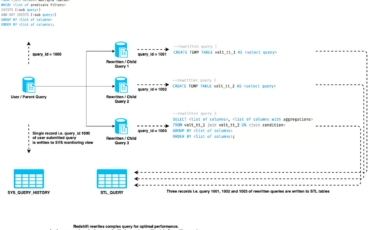
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud, providing up Read More →
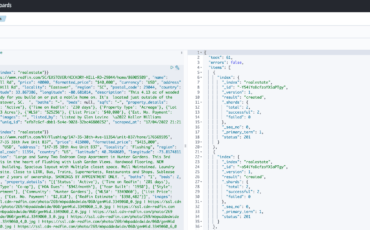
With the release of Amazon OpenSearch Service 2.5, you can create maps with multiple layers Read More →
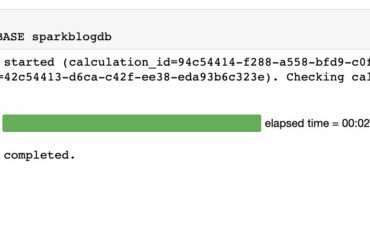
At AWS re:Invent 2022, Amazon Athena launched support for Apache Spark. With this launch, Amazon Read More →
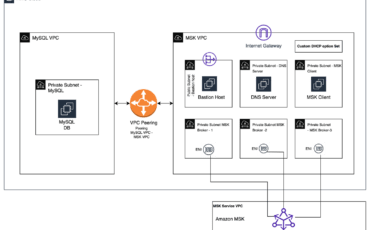
Amazon MSK Connect is a feature of Amazon Managed Streaming for Apache Kafka (Amazon MSK) Read More →
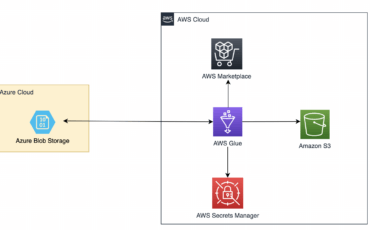
Today, we are pleased to announce new AWS Glue connectors for Azure Blob Storage and Read More →
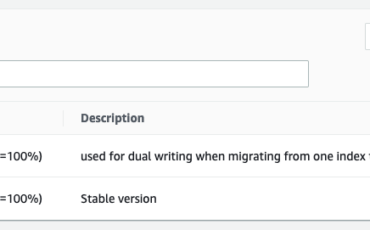
SmugMug operates two very large online photo platforms, SmugMug and Flickr, enabling more than 100 Read More →
Data lakes and data warehouses are two of the most important data storage and management Read More →
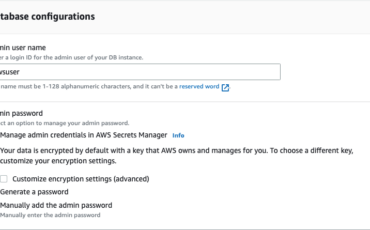
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can Read More →
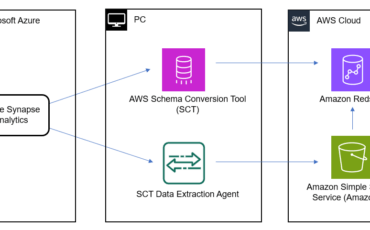
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse that provides the flexibility to Read More →
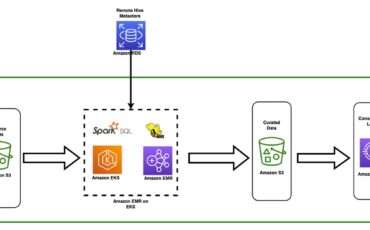
Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive Read More →
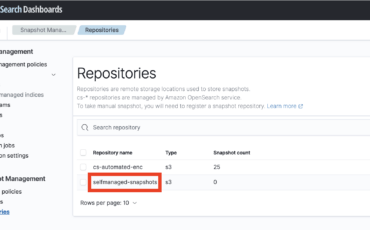
Data is the lifeblood of any organization, and the importance of protecting it cannot be Read More →

Where does big data come from? Big data is generated primarily by three sources: Business Read More →
![]()
