Data lakes and data warehouses are two of the most important data storage and management technologies in a modern data architecture. Data lakes store all of an organization’s data, regardless of its format or structure. An open table format such as Apache Hudi, Delta Lake, or Apache Iceberg is widely used to build data lakes on Amazon Simple Storage Service (Amazon S3) in a transactionally consistent manner for use cases including record-level upserts and deletes, change data capture (CDC), time travel queries, and more. Data warehouses, on the other hand, store data that has been cleaned, organized, and structured for analysis. Depending on your use case, it’s common to have a copy of the data between your data lake and data warehouse to support different access patterns.
When the data becomes very large and unwieldy, it can be difficult to keep the copy of the data between data lakes and data warehouses in sync and up to date in an efficient manner.
In this post, we discuss different architecture patterns to keep data in sync and up to date between data lakes built on open table formats and data warehouses such as Amazon Redshift. We also discuss the benefits of incremental loading and the techniques for implementing the architecture using AWS Glue, which is a serverless, scalable data integration service that helps you discover, prepare, move, and integrate data from multiple sources. Various data stores are supported in AWS Glue; for example, AWS Glue 4.0 supports an enhanced Amazon Redshift connector to read from and write to Amazon Redshift, and also supports a built-in Snowflake connector to read from and write to Snowflake. Moreover, Apache Hudi, Delta Lake, and Apache Iceberg are natively supported in AWS Glue.
Architecture patterns
Generally, there are three major architecture patterns to keep your copy of data between data lakes and data warehouses in sync and up to date:
- Dual writes
- Incremental queries
- Change data capture
Let’s discuss each of the architecture patterns and the techniques to achieve them.
Dual writes
When initially ingesting data from its raw source into the data lake and data warehouse, a single batch process is configured to write to both. We call this pattern dual writes. Although this architecture pattern (see the following diagram) is straightforward and easy to implement, it can become error-prone because there are two separate transactions threads, and each can have its own errors, causing inconsistencies between the data lake and data warehouse when a write fails in one but not both.
![]()
Incremental queries
An incremental query architectural pattern is designed to ingest data first into the data lake with an open table format, and then load the newly written data from the data lake into the data warehouse. Open table formats such as Apache Hudi and Apache Iceberg support incremental queries based on their respective transaction logs. You can capture records inserted or updated with the incremental queries, and then merge the captured records into the destination data warehouses.
Apache Hudi supports incremental query, which allows you to retrieve all records written during specific time range.
Delta Lake doesn’t have a specific concept for incremental queries. It’s covered in a change data feed, which is explained in the next section.
Apache Iceberg supports incremental read, which allows you to read appended data incrementally. As of this writing, Iceberg gets incremental data only from the append operation; other operations such as replace, overwrite, and delete aren’t supported by incremental read.
For merging the records into Amazon Redshift, you can use the MERGE SQL command, which was released in April 2023. AWS Glue supports the Redshift MERGE SQL command within its data integration jobs. To learn more, refer to Exploring new ETL and ELT capabilities for Amazon Redshift from the AWS Glue Studio visual editor.
Incremental queries are useful to capture changed records; however, incremental queries can’t handle the deletes and just send the latest version of each record. If you need to handle delete operations in the source data lake, you will need to use a CDC-based approach.
The following diagram illustrates an incremental query architectural pattern.
![]()
Change data capture
Change data capture (CDC) is a well-known technique to capture all mutating operations in a source database system and relay those operations to another system. CDC keeps all the intermediate changes, including the deletes. With this architecture pattern, you capture not only inserts and updates, but also deletes committed to the data lake, and then merge those captured changes into the data warehouses.
Apache Hudi 0.13.0 or later supports change data capture as an experimental feature, which is only available for Copy-on-Write (CoW) tables. Merge-on-Read tables (MoR) do not support CDC as of this writing.
Delta Lake 2.0.0 or later supports a change data feed, which allows Delta tables to track record-level changes between table versions.
Apache Iceberg 1.2.1 or later supports change data capture through its create_changelog_view procedure. When you run this procedure, a new view that contains the changes from a given table is created.
The following diagram illustrates a CDC architecture.
![]()
Example scenario
To demonstrate the end-to-end experience, this post uses the Global Historical Climatology Network Daily (GHCN-D) dataset. The data is publicly accessible through an S3 bucket. For more information, see the Registry of Open Data on AWS. You can also learn more in Visualize over 200 years of global climate data using Amazon Athena and Amazon QuickSight.
The Amazon S3 location s3://noaa-ghcn-pds/csv/by_year/ has all of the observations from 1763 to the present organized in CSV files, one file for each year. The following block shows an example of what the records look like:
The records have fields including ID, DATE, ELEMENT, and more. Each combination of ID, DATE, and ELEMENT represents a unique record in this dataset. For example, the record with ID as AE000041196, ELEMENT as TAVG, and DATE as 20220101 is unique. We use this dataset in the following examples and simulate record-level updates and deletes as sample operations.
Prerequisites
To continue with the examples in this post, you need to create (or already have) the following AWS resources:
For the first tutorial (loading from Apache Hudi to Amazon Redshift), you also need the following:
For the second tutorial (loading from Delta Lake to Snowflake), you need the following:
- A Snowflake account.
- An AWS Glue connection named
snowflakefor Snowflake access. For more information, refer to Configuring Snowflake connections. - An AWS Secrets Manager secret named
snowflake_credentialswith the following key pairs:- Key
sfUserwith value<Your Snowflake username> - Key
sfPasswordwith value<Your Snowflake password>
- Key
These tutorials are inter-changeable, so you can easily apply the same pattern for any combination of source and destination, for example, Hudi to Snowflake, or Delta to Amazon Redshift.
Load data incrementally from Apache Hudi table to Amazon Redshift using a Hudi incremental query
This tutorial uses Hudi incremental queries to load data from a Hudi table and then merge the changes to Amazon Redshift.
Ingest initial data to a Hudi table
Complete the following steps:
- Open AWS Glue Studio.
- Choose ETL jobs.
- Choose Visual with a source and target.
- For Source and Target, choose Amazon S3, then choose Create.
A new visual job configuration appears. The next step is to configure the data source to read an example dataset.
- Name this new job
hudi-data-ingestion. - Under Visual, choose Data source – S3 bucket.
- Under Node properties, for S3 source type, select S3 location.
- For S3 URL, enter
s3://noaa-ghcn-pds/csv/by_year/2022.csv.
The data source is configured. The next step is to configure the data target to ingest data in Apache Hudi on your S3 bucket.
- Choose Data target – S3 bucket.
- Under Data target properties – S3, for Format, choose Apache Hudi.
- For Hudi Table Name, enter
ghcn_hudi. - For Hudi Storage Type, choose Copy on write.
- For Hudi Write Operation, choose Upsert.
- For Hudi Record Key Fields, choose
ID. - For Hudi Precombine Key Field, choose
DATE. - For Compression Type, choose GZIP.
- For S3 Target location, enter
s3://<Your S3 bucket name>/<Your S3 bucket prefix>/hudi_incremental/ghcn/. (Provide your S3 bucket name and prefix.) - For Data Catalog update options, select Do not update the Data Catalog.
Now your data integration job is authored in the visual editor completely. Let’s add one remaining setting about the IAM role, then run the job.
- Under Job details, for IAM Role, choose your IAM role.
- Choose Save, then choose Run.
![]()
You can track the progress on the Runs tab. It finishes in several minutes.
Load data from the Hudi table to a Redshift table
In this step, we assume that the files are updated with new records every day, and want to store only the latest record per the primary key (ID and ELEMENT) to make the latest snapshot data queryable. One typical approach is to do an INSERT for all the historical data, and calculate the latest records in queries; however, this can introduce additional overhead in all the queries. When you want to analyze only the latest records, it’s better to do an UPSERT (update and insert) based on the primary key and DATE field rather than just an INSERT in order to avoid duplicates and maintain a single updated row of data.
Complete the following steps to load data from the Hudi table to a Redshift table:
- Download the file hudi2redshift-incremental-load.ipynb.
- In AWS Glue Studio, choose Jupyter Notebook, then choose Create.
- For Job name, enter
hudi-ghcn-incremental-load-notebook. - For IAM Role, choose your IAM role.
- Choose Start notebook.
Wait for the notebook to be ready.
- Run the first cell to set up an AWS Glue interactive session.

- Replace the parameters with yours and run the cell under Configure your resource.

- Run the cell under Initialize SparkSession and GlueContext.
- Run the cell under Determine target time range for incremental query.
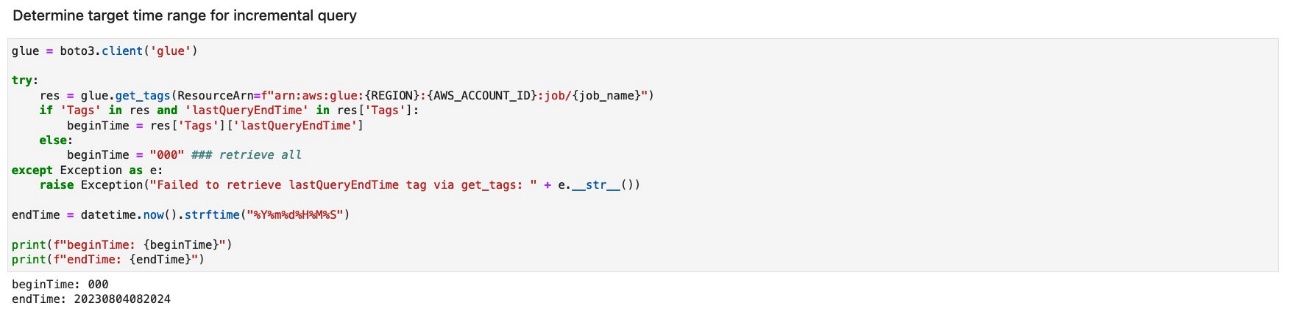
- Run the cells under Run query to load data updated during a given timeframe.
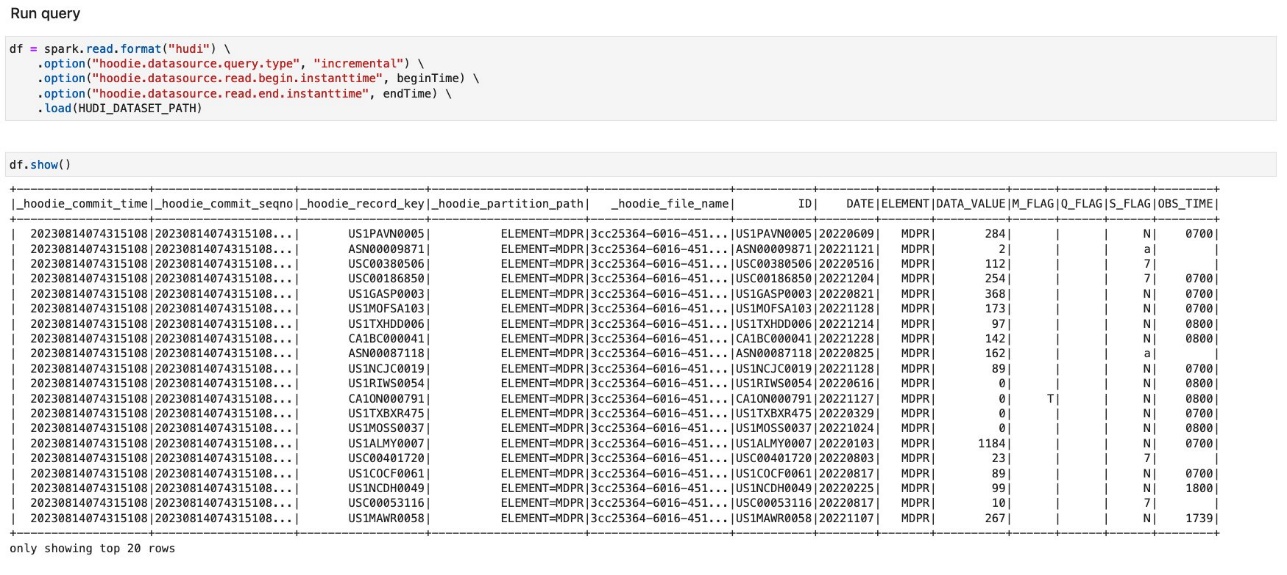
- Run the cells under Merge changes into destination table.
You can see the exact query immediately run right after ingesting a temp table into the Redshift table.
![]()
- Run the cell under Update the last query end time.
Validate initial records in the Redshift table
Complete the following steps to validate the initial records in the Redshift table:
- On the Amazon Redshift console, open Query Editor v2.
- Run the following query:
The query returns the following result set.
![]()
The original source file 2022.csv has historical records for record ID='AE000041196' from 20220101 to 20221231; however, the query result shows only four records, one record per ELEMENT at the latest snapshot of the day 20221230 or 20221231. Because we used the UPSERT write option when writing data, we configured the ID field as a Hudi record key field, the DATE field as a Hudi precombine field, and the ELEMENT field as partition key field. When two records have the same key value, Hudi picks the one with the largest value for the precombine field. When the job ingested data, it compared all the values in the DATE field for each pair of ID and ELEMENT, and then picked the record with the largest value in the DATE field. We use the current state of this table as an initial state.
Ingest updates to a Hudi table
Complete the following steps to simulating ingesting more records to the Hudi table:
- On AWS Glue Studio, choose the job
hudi-data-ingestion. - On the Data target – S3 bucket node, change the S3 location from
s3://noaa-ghcn-pds/csv/by_year/2022.csv to s3://noaa-ghcn-pds/csv/by_year/2023.csv. - Run the job.
Because this job uses the DATE field as a Hudi precombine field, the records included in the new source file have been upserted into the Hudi table.
Load data incrementally from the Hudi table to the Redshift table
Complete the following steps to load the ingested records incrementally to the Redshift table:
- On AWS Glue Studio, choose the job
hudi-ghcn-incremental-load-notebook. - Run all the cells again.
In the cells under Run query, you will notice that the records shown this time have DATE in 2023. Only newly ingested records are shown here.
![]()
In the cells under Merge changes into destination table, the newly ingested records are merged into the Redshift table. The generated MERGE query statement in the notebook is as follows:
The next step is to verify the result on the Redshift side.
Validate updated records in the Redshift table
Complete the following steps to validate the updated records in the Redshift table:
- On the Amazon Redshift console, open Query Editor v2.
- Run the following query:
The query returns the following result set.
![]()
Now you see that the four records have been updated with the new records in 2023. If you have further future records, this approach works well to upsert new records based on the primary keys.
Load data incrementally from a Delta Lake table to Snowflake using a Delta change data feed
This tutorial uses a Delta change data feed to load data from a Delta table, and then merge the changes to Snowflake.
Ingest initial data to a Delta table
Complete the following steps:
- Open AWS Glue Studio.
- Choose ETL jobs.
- Choose Visual with a source and target.
- For Source and Target, choose Amazon S3, then choose Create.
A new visual job configuration appears. The next step is to configure the data source to read an example dataset.
- Name this new job
delta-data-ingestion. - Under Visual, choose Data source – S3 bucket.
- Under Node properties, for S3 source type, select S3 location.
- For S3 URL, enter
s3://noaa-ghcn-pds/csv/by_year/2022.csv.
The data source is configured. The next step is to configure the data target to ingest data in Apache Hudi on your S3 bucket.
- Choose Data target – S3 bucket.
- Under Data target properties – S3, for Format, choose Delta Lake.
- For Compression Type, choose Snappy.
- For S3 Target location, enter
s3://<Your S3 bucket name>/<Your S3 bucket prefix>/delta_incremental/ghcn/. (Provide your S3 bucket name and prefix.) - For Data Catalog update options, select Do not update the Data Catalog.
Now your data integration job is authored in the visual editor completely. Let’s add an additional detail about the IAM role and job parameters, and then run the job.
- Under Job details, for IAM Role, choose your IAM role.
- Under Job parameters, for Key, enter
--confand for Value, enterspark.databricks.delta.properties.defaults.enableChangeDataFeed=true. - Choose Save, then choose Run.
Load data from the Delta table to a Snowflake table
Complete the following steps to load data from the Delta table to a Snowflake table:
- Download the file delta2snowflake-incremental-load.ipynb.
- On AWS Glue Studio, choose Jupyter Notebook, then choose Create.
- For Job name, enter
delta-ghcn-incremental-load-notebook. - For IAM Role, choose your IAM role.
- Choose Start notebook.
Wait for the notebook to be ready.
- Run the first cell to start an AWS Glue interactive session.
- Replace the parameters with yours and run the cell under Configure your resource.

- Run the cell under Initialize SparkSession and GlueContext.
- Run the cell under Determine target time range for CDC.
- Run the cells under Run query to load data updated during a given timeframe.
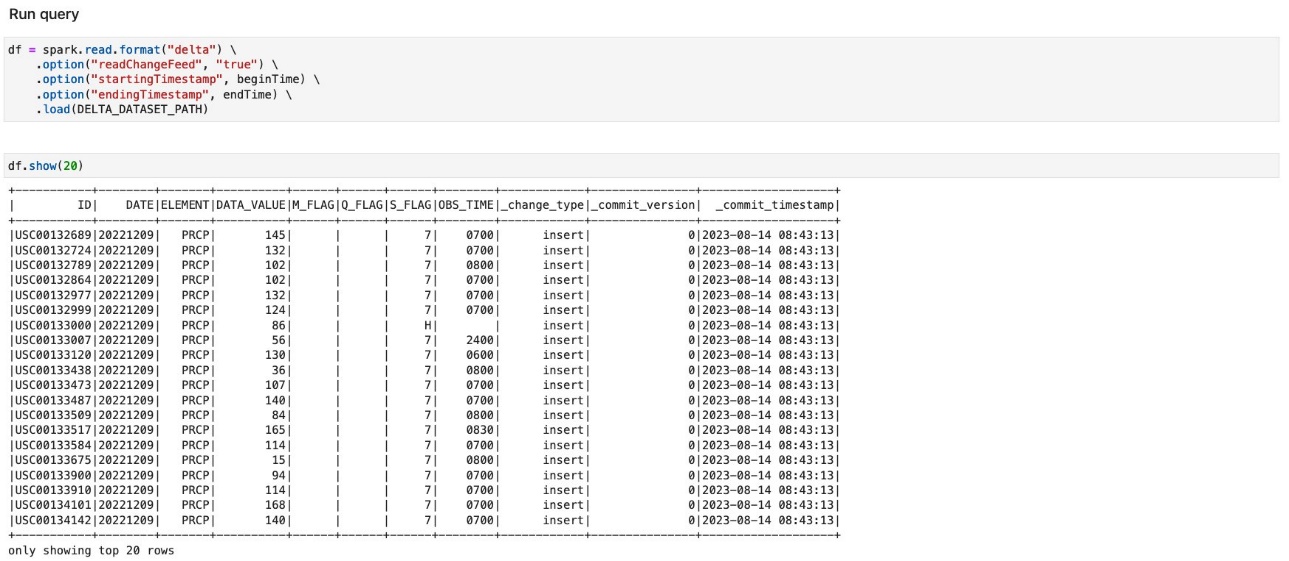
- Run the cells under Merge changes into destination table.
You can see the exact query immediately run right after ingesting a temp table in the Snowflake table.
![]()
![]()
- Run the cell under Update the last query end time.
Validate initial records in the Snowflake warehouse
Run the following query in Snowflake:
The query should return the following result set:
![]()
There are three records returned in this query.
Update and delete a record on the Delta table
Complete the following steps to update and delete a record on the Delta table as sample operations:
- Return to the AWS Glue notebook job.
- Run the cells under Update the record and Delete the record.
![]()
Load data incrementally from the Delta table to the Snowflake table
Complete the following steps to load the ingested records incrementally to the Redshift table:
- On AWS Glue Studio, choose the job
delta-ghcn-incremental-load-notebook. - Run all the cells again.
When you run the cells under Run query, you will notice that there are only three records, which correspond to the update and delete operation performed in the previous step.
![]()
In the cells under Merge changes into destination table, the changes are merged into the Snowflake table. The generated MERGE query statement in the notebook is as follows:
The next step is to verify the result on the Snowflake side.
Validate updated records in the Snowflake table
Complete the following steps to validate the updated and deleted records in the Snowflake table:
- On Snowflake, run the following query:
The query returns the following result set:
![]()
You will notice that the query only returns two records. The value of DATA_VALUE of the record ELEMENT=PRCP has been updated from 0 to 12345. The record ELEMENT=TMAX has been deleted. This means that your update and delete operations on the source Delta table have been successfully replicated to the target Snowflake table.
Clean up
Complete the following steps to clean up your resources:
- Delete the following AWS Glue jobs:
hudi-data-ingestionhudi-ghcn-incremental-load-notebookdelta-data-ingestiondelta-ghcn-incremental-load-notebook
- Clean up your S3 bucket.
- If needed, delete the Redshift cluster or the Redshift Serverless workgroup.
Conclusion
This post discussed architecture patterns to keep a copy of your data between data lakes using open table formats and data warehouses in sync and up to date. We also discussed the benefits of incremental loading and the techniques for achieving the use case using AWS Glue. We covered two use cases: incremental load from a Hudi table to Amazon Redshift, and from a Delta table to Snowflake.
About the author
![]() Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He works based in Tokyo, Japan. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
