As the scale and complexity of microservices and distributed applications continues to expand, customers are seeking guidance for building cost-efficient infrastructure supporting operational analytics use cases. Operational analytics is a popular use case with Amazon OpenSearch Service. A few of the defining characteristics of these use cases are ingesting a high volume of time series data and a relatively low volume of querying, alerting, and running analytics on ingested data for real-time insights. Although OpenSearch Service is capable of ingesting petabytes of data across storage tiers, you still have to provision capacity to migrate between hot and warm tiers. This adds to the cost of provisioned OpenSearch Service domains.
The time series data often contains logs or telemetry data from various sources with different values and needs. That is, logs from some sources need to be available in a hot storage tier longer, whereas logs from other sources can tolerate a delay in querying and other requirements. Until now, customers were building external ingestion systems with the Amazon Kinesis family of services, Amazon Simple Queue Service (Amazon SQS), AWS Lambda, custom code, and other similar solutions. Although these solutions enable ingestion of operational data with various requirements, they add to the cost of ingestion.
In general, operational analytics workloads use anomaly detection to aid domain operations. This assumes that the data is already present in OpenSearch Service and the cost of ingestion is already borne.
With the addition of a few recent features of Amazon OpenSearch Ingestion, a fully managed serverless pipeline for OpenSearch Service, you can effectively address each of these cost points and build a cost-effective solution. In this post, we outline a solution that does the following:
- Uses conditional routing of Amazon OpenSearch Ingestion to separate logs with specific attributes and store those, for example, in Amazon OpenSearch Service and archive all events in Amazon S3 to query with Amazon Athena
- Uses in-stream anomaly detection with OpenSearch Ingestion, thereby removing the cost associated with compute needed for anomaly detection after ingestion
In this post, we use a VPC flow logs use case to demonstrate the solution. The solution and pattern presented in this post is equally applicable to larger operational analytics and observability use cases.
Solution overview
We use VPC flow logs to capture IP traffic and trigger processing notifications to the OpenSearch Ingestion pipeline. The pipeline filters the data, routes the data, and detects anomalies. The raw data will be stored in Amazon S3 for archival purposes, then the pipeline will detect anomalies in the data in near-real time using the Random Cut Forest (RCF) algorithm and send those data records to OpenSearch Service. The raw data stored in Amazon S3 can be inexpensively retained for an extended period of time using tiered storage and queried using the Athena query engine, and also visualized using Amazon QuickSight or other data visualization services. Although this walkthrough uses VPC flow log data, the same pattern applies for use with AWS CloudTrail, Amazon CloudWatch, any log files as well as any OpenTelemetry events, and custom producers.
The following is a diagram of the solution that we configure in this post.
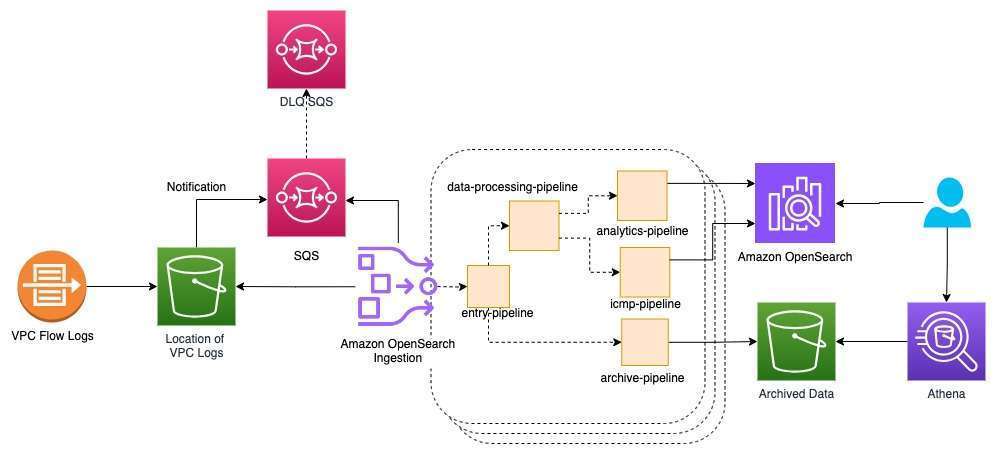
In the following sections, we provide a walkthrough for configuring this solution.
The patterns and procedures presented in this post have been validated with the current version of OpenSearch Ingestion and the Data Prepper open-source project version 2.4.
Prerequisites
Complete the following prerequisite steps:
- We will be using a VPC for demonstration purposes for generating data. Set up the VPC flow logs to publish logs to an S3 bucket in text format. To optimize S3 storage costs, create a lifecycle configuration on the S3 bucket to transition the VPC flow logs to different tiers or expire processed logs. Make a note of the S3 bucket name you configured to use in later steps.
- Set up an OpenSearch Service domain. Make a note of the domain URL. The domain can be either public or VPC based, which is the preferred configuration.
- Create an S3 bucket for storing archived events, and make a note of S3 bucket name. Configure a resource-based policy allowing OpenSearch Ingestion to archive logs and Athena to read the logs.
- Configure an AWS Identity and Access Management (IAM) role or separate IAM roles allowing OpenSearch Ingestion to interact with Amazon SQS and Amazon S3. For instructions, refer to Configure the pipeline role.
- Configure Athena or validate that Athena is configured on your account. For instructions, refer to Getting started.
Configure an SQS notification
VPC flow logs will write data in Amazon S3. After each file is written, Amazon S3 will send an SQS notification to notify the OpenSearch Ingestion pipeline that the file is ready for processing.
If the data is already stored in Amazon S3, you can use the S3 scan capability for a one-time or scheduled loading of data through the OpenSearch Ingestion pipeline.
Use AWS CloudShell to issue the following commands to create the SQS queues VpcFlowLogsNotifications and VpcFlowLogsNotifications-DLQ that we use for this walkthrough.
Create a dead-letter queue with the following code
Create an SQS queue to receive events from Amazon S3 with the following code:
To configure the S3 bucket to send events to the SQS queue, use the following code (provide the name of your S3 bucket used for storing VPC flow logs):
Create the OpenSearch Ingestion pipeline
Now that you have configured Amazon SQS and the S3 bucket notifications, you can configure the OpenSearch Ingestion pipeline.
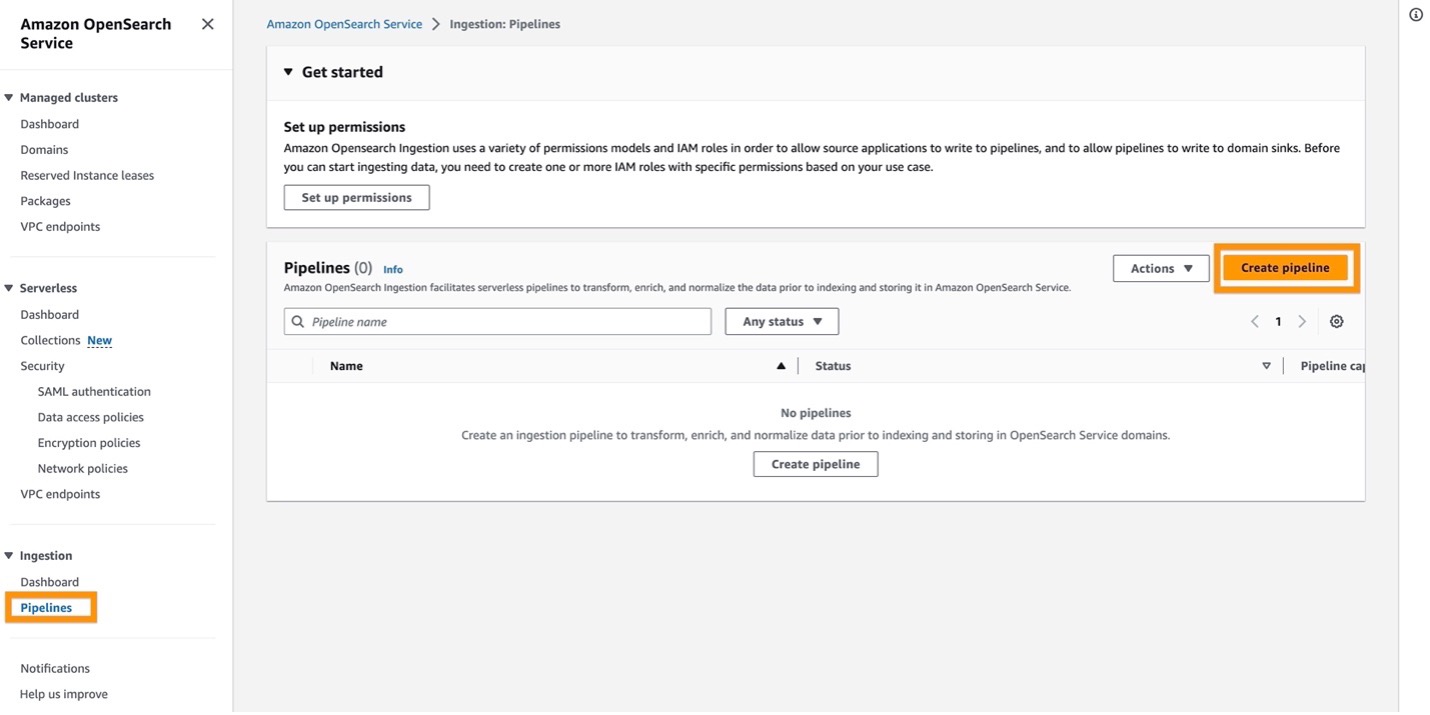
- On the OpenSearch Service console, choose Pipelines under Ingestion in the navigation pane.
- Choose Create pipeline.
- For Pipeline name, enter a name (for this post, we use
stream-analytics-pipeline). - For Pipeline configuration, enter the following code:
Replace the variables in the preceding code with resources in your account:
-
__SQS_QUEUE_URL__– URL of Amazon SQS for Amazon S3 events__STS_ROLE_ARN__– AWS Security Token Service (AWS STS) roles for resources to assume__AWS_S3_BUCKET_ARCHIVE__– S3 bucket for archiving processed events__AMAZON_OPENSEARCH_DOMAIN_URL__– URL of OpenSearch Service domain__REGION__– Region (for example, us-east-1)
- In the Network settings section, specify your network access. For this walkthrough, we are using VPC access. We provided the VPC and private subnet locations that have connectivity with the OpenSearch Service domain and security groups.
- Leave the other settings with default values, and choose Next.
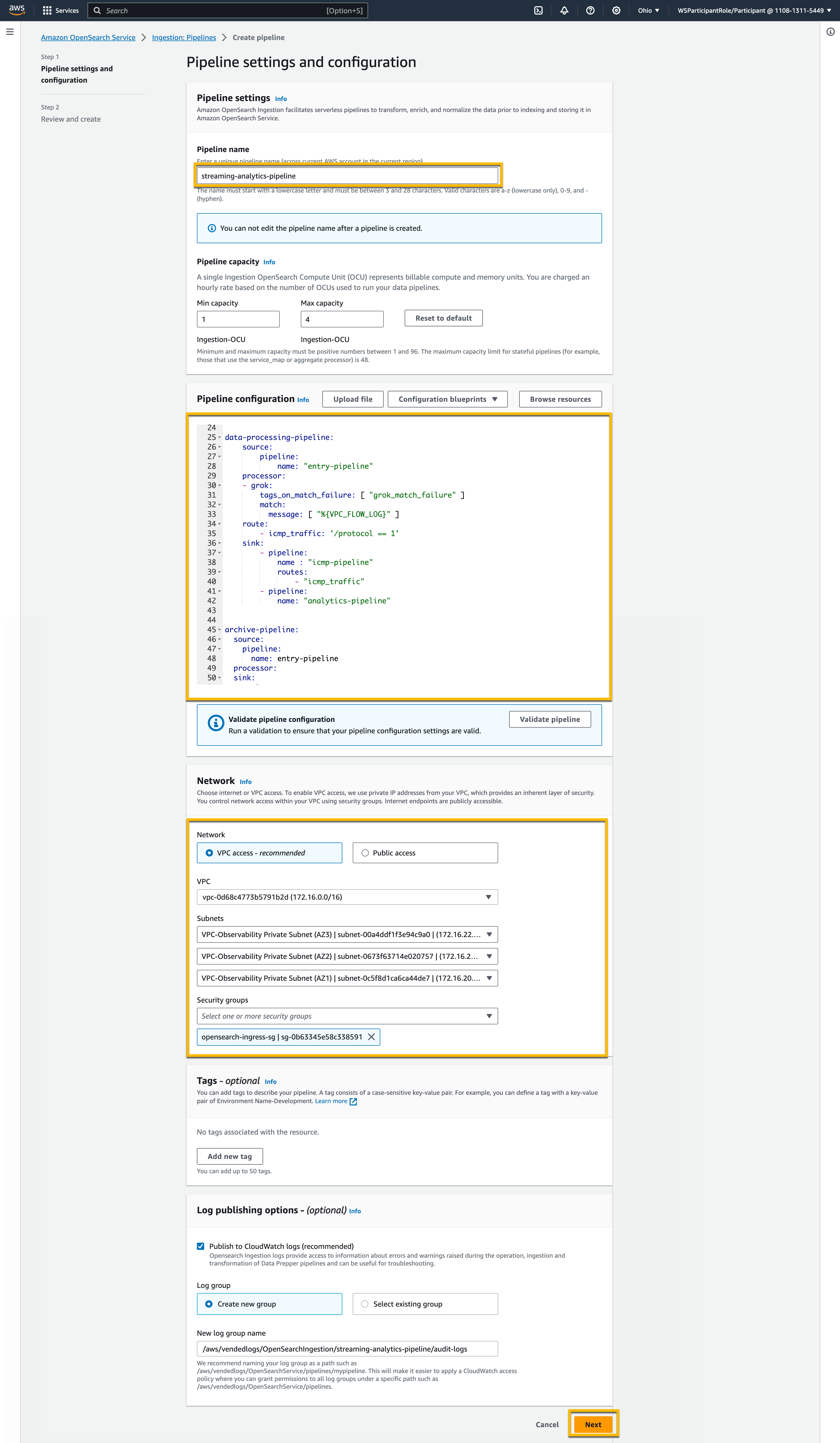
- Review the configuration changes and choose Create pipeline.
It will take a few minutes for OpenSearch Service to provision the environment. While the environment is being provisioned, we’ll walk you through the pipeline configuration. Entry-pipeline listens for SQS notifications about newly arrived files and triggers the reading of VPC flow log compressed files:
The pipeline branches into two sub-pipelines. The first stores original messages for archival purposes in Amazon S3 in read-optimized Parquet format; the other applies analytics routes events to the OpenSearch Service domain for fast querying and alerting:
The pipeline archive-pipeline aggregates messages in 50 MB chunks or every 60 seconds and writes a Parquet file to Amazon S3 with the schema inferred from the message. Also, a prefix is added to help with partitioning and query optimization when reading a collection of files using Athena.
Now that we have reviewed the basics, we focus on the pipeline that detects anomalies and sends only high-value messages that deviate from the norm to OpenSearch Service. It also stores Internet Control Message Protocols (ICMP) messages in OpenSearch Service.
We applied a grok processor to parse the message using a predefined regex for parsing VPC flow logs, and also tagged all unparsable messages with the grok_match_failure tag, which we use to remove headers and other records that can’t be parsed:
We then routed all messages with the protocol identifier 1 (ICMP) to icmp-pipeline and all messages to analytics-pipeline for anomaly detection:
In the analytics pipeline, we dropped all records that can’t be parsed using the hasTags method based on the tag that we assigned at the time of parsing. We also removed all records that don’t contains useful data for anomaly detection.
Then we applied probabilistic sampling using the tail_sampler processor for all accepted messages grouped by source and destination addresses and sent those to the sink with all messages that were not accepted. This helps reduce the volume of messages within the selected cardinality keys, with a focus on all messages that weren’t accepted, and keeps a sample representation of messages that were accepted.
Then we used the anomaly detector processor to identify anomalies within the cardinality key pairs or source and destination addresses in our example. The anomaly detector processor creates and trains RCF models for a hashed value of keys, then uses those models to determine whether newly arriving messages have an anomaly based on the trained data. In our demonstration, we use bytes data to detect anomalies:
We set verbose:true to instruct the detector to emit the message every time an anomaly is detected. Also, for this walkthrough, we used a non-default sample_size for training the model.
When anomalies are detected, the anomaly detector returns a complete record and adds
"deviation_from_expected":value,"grade":value attributes that signify the deviation value and severity of the anomaly. These values can be used to determine routing of such messages to OpenSearch Service, and use per-document monitoring capabilities in OpenSearch Service to alert on specific conditions.
Currently, OpenSearch Ingestion creates up to 5,000 distinct models based on cardinality key values per compute unit. This limit is observed using the anomaly_detector.RCFInstances.value CloudWatch metric. It’s important to select a cardinality key-value pair to avoid exceeding this constraint. As development of the Data Prepper open-source project and OpenSearch Ingestion continues, more configuration options will be added to offer greater flexibility around model training and memory management.
The OpenSearch Ingestion pipeline exposes the anomaly_detector.cardinalityOverflow.count metric through CloudWatch. This metric indicates a number of key value pairs that weren’t run by the anomaly detection processor during a period of time as the maximum number of RCFInstances per compute unit was reached. To avoid this constraint, a number of compute units can be scaled out to provide additional capacity for hosting additional instances of RCFInstances.
In the last sink, the pipeline writes records with detected anomalies along with deviation_from_expected and grade attributes to the OpenSearch Service domain:
Because only anomaly records are being routed and written to the OpenSearch Service domain, we are able to significantly reduce the size of our domain and optimize the cost of our sample observability infrastructure.
Another sink was used for storing all ICMP records in a separate index in the OpenSearch Service domain:
Query archived data from Amazon S3 using Athena
In this section, we review the configuration of Athena for querying archived events data stored in Amazon S3. Complete the following steps:
- Navigate to the Athena query editor and create a new database called
vpc-flow-logs-archive-database using the following command:
- 2. On the Database menu, choose
vpc-flow-logs-archive. - In the query editor, enter the following command to create a table (provide the S3 bucket used for archiving processed events). For simplicity, for this walkthrough, we create a table without partitions.
- Run the following query to validate that you can query the archived VPC flow log data:
Because archived data is stored in its original format, it helps avoid issues related to format conversion. Athena will query and display records in the original format. However, it’s ideal to interact only with a subset of columns or parts of the messages. You can use the regexp_split function in Athena to split the message in the columns and retrieve certain columns. Run the following query to see the source and destination address groupings from the VPC flow log data:
This demonstrated that you can query all events using Athena, where archived data in its original raw format is used for the analysis. Athena is priced per data scanned. Because the data is stored in a read-optimized format and partitioned, it enables further cost-optimization around on-demand querying of archived streaming and observability data.
Clean up
To avoid incurring future charges, delete the following resources created as part of this post:
- OpenSearch Service domain
- OpenSearch Ingestion pipeline
- SQS queues
- VPC flow logs configuration
- All data stored in Amazon S3
Conclusion
In this post, we demonstrated how to use OpenSearch Ingestion pipelines to build a cost-optimized infrastructure for log analytics and observability events. We used routing, filtering, aggregation, and anomaly detection in an OpenSearch Ingestion pipeline, enabling you to downsize your OpenSearch Service domain and create a cost-optimized observability infrastructure. For our example, we used a data sample with 1.5 million events with a pipeline distilling to 1,300 events with predicted anomalies based on source and destination IP pairs. This metric demonstrates that the pipeline identified that less than 0.1% of events were of high importance, and routed those to OpenSearch Service for visualization and alerting needs. This translates to lower resource utilization in OpenSearch Service domains and can lead to provisioning of smaller OpenSearch Service environments.
We encourage you to use OpenSearch Ingestion pipelines to create your purpose-built and cost-optimized observability infrastructure that uses OpenSearch Service for storing and alerting on high-value events. If you have comments or feedback, please leave them in the comments section.
About the Authors
 Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services.
Mikhail Vaynshteyn is a Solutions Architect with Amazon Web Services. Mikhail works with healthcare and life sciences customers to build solutions that help improve patients’ outcomes. Mikhail specializes in data analytics services.
 Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
Muthu Pitchaimani is a Search Specialist with Amazon OpenSearch Service. He builds large-scale search applications and solutions. Muthu is interested in the topics of networking and security, and is based out of Austin, Texas.
