This post is written in collaboration with Elijah Ball from Ontraport. Customers are implementing data Read More →
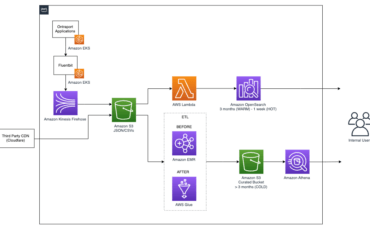
This post is written in collaboration with Elijah Ball from Ontraport. Customers are implementing data Read More →
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Read More →
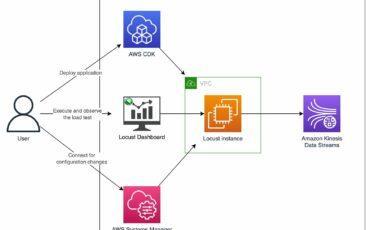
Building a streaming data solution requires thorough testing at the scale it will operate in Read More →
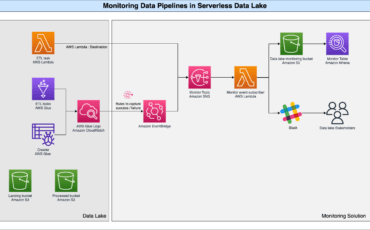
AWS serverless services, including but not limited to AWS Lambda, AWS Glue, AWS Fargate, Amazon Read More →
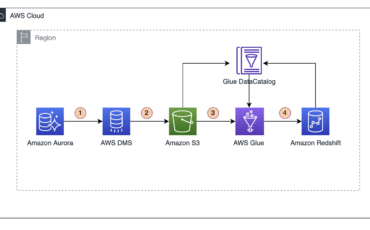
Data has become an integral part of most companies, and the complexity of data processing Read More →

Apache Flink and Apache Spark are both open-source, distributed data processing frameworks used widely for Read More →

Amazon Redshift is a petabyte-scale, enterprise-grade cloud data warehouse service delivering the best price-performance. Today, Read More →
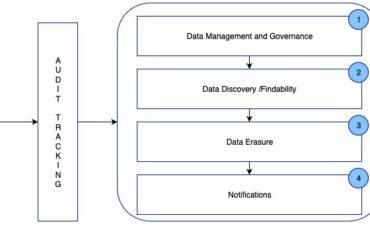
The GDPR (General Data Protection Regulation) right to be forgotten, also known as the right Read More →
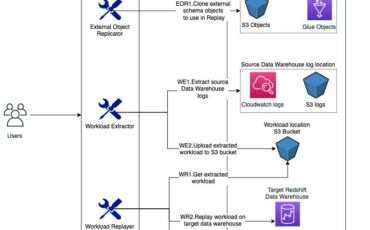
Amazon Redshift is a widely used, fully managed, petabyte-scale cloud data warehouse. Tens of thousands Read More →
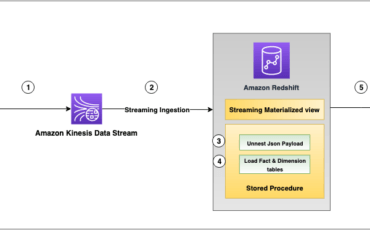
Amazon Redshift is a fully managed, scalable cloud data warehouse that accelerates your time to Read More →
![]()
