In today’s data-driven world, the ability to effortlessly move and analyze data across diverse platforms is essential. Amazon AppFlow, a fully managed data integration service, has been at the forefront of streamlining data transfer between AWS services, software as a service (SaaS) applications, and now Google BigQuery. In this blog post, you explore the new Google BigQuery connector in Amazon AppFlow and discover how it simplifies the process of transferring data from Google’s data warehouse to Amazon Simple Storage Service (Amazon S3), providing significant benefits for data professionals and organizations, including the democratization of multi-cloud data access.
Overview of Amazon AppFlow
Amazon AppFlow is a fully managed integration service that you can use to securely transfer data between SaaS applications such as Google BigQuery, Salesforce, SAP, Hubspot, and ServiceNow, and AWS services such as Amazon S3 and Amazon Redshift, in just a few clicks. With Amazon AppFlow, you can run data flows at nearly any scale at the frequency you choose—on a schedule, in response to a business event, or on demand. You can configure data transformation capabilities such as filtering and validation to generate rich, ready-to-use data as part of the flow itself, without additional steps. Amazon AppFlow automatically encrypts data in motion, and allows you to restrict data from flowing over the public internet for SaaS applications that are integrated with AWS PrivateLink, reducing exposure to security threats.
Introducing the Google BigQuery connector
The new Google BigQuery connector in Amazon AppFlow unveils possibilities for organizations seeking to use the analytical capability of Google’s data warehouse, and to effortlessly integrate, analyze, store, or further process data from BigQuery, transforming it into actionable insights.
Architecture
Let’s review the architecture to transfer data from Google BigQuery to Amazon S3 using Amazon AppFlow.
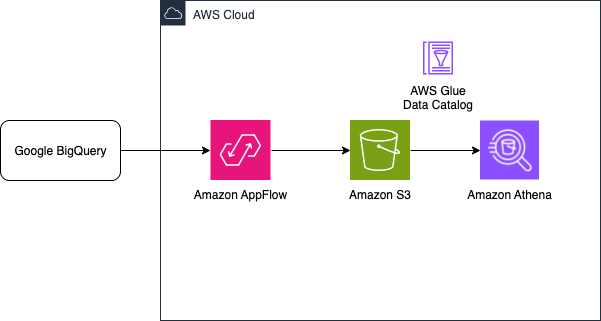
- Select a data source: In Amazon AppFlow, select Google BigQuery as your data source. Specify the tables or datasets you want to extract data from.
- Field mapping and transformation: Configure the data transfer using the intuitive visual interface of Amazon AppFlow. You can map data fields and apply transformations as needed to align the data with your requirements.
- Transfer frequency: Decide how frequently you want to transfer data—such as daily, weekly, or monthly—supporting flexibility and automation.
- Destination: Specify an S3 bucket as the destination for your data. Amazon AppFlow will efficiently move the data, making it accessible in your Amazon S3 storage.
- Consumption: Use Amazon Athena to analyze the data in Amazon S3.
Prerequisites
The dataset used in this solution is generated by Synthea, a synthetic patient population simulator and opensource project under the Apache License 2.0. Load this data into Google BigQuery or use your existing dataset.
Connect Amazon AppFlow to your Google BigQuery account
For this post, you use a Google account, OAuth client with appropriate permissions, and Google BigQuery data. To enable Google BigQuery access from Amazon AppFlow, you must set up a new OAuth client in advance. For instructions, see Google BigQuery connector for Amazon AppFlow.
Set up Amazon S3
Every object in Amazon S3 is stored in a bucket. Before you can store data in Amazon S3, you must create an S3 bucket to store the results.
Create a new S3 bucket for Amazon AppFlow results
To create an S3 bucket, complete the following steps:
- On the AWS Management console for Amazon S3, choose Create bucket.
- Enter a globally unique name for your bucket; for example,
appflow-bq-sample. - Choose Create bucket.
Create a new S3 bucket for Amazon Athena results
To create an S3 bucket, complete the following steps:
- On the AWS Management console for Amazon S3, choose Create bucket.
- Enter a globally unique name for your bucket; for example,
athena-results. - Choose Create bucket.
User role (IAM role) for AWS Glue Data Catalog
To catalog the data that you transfer with your flow, you must have the appropriate user role in AWS Identity and Access Management (IAM). You provide this role to Amazon AppFlow to grant the permissions it needs to create an AWS Glue Data Catalog, tables, databases, and partitions.
For an example IAM policy that has the required permissions, see Identity-based policy examples for Amazon AppFlow.
Walkthrough of the design
Now, let’s walk through a practical use case to see how the Amazon AppFlow Google BigQuery to Amazon S3 connector works. For the use case, you will use Amazon AppFlow to archive historical data from Google BigQuery to Amazon S3 for long-term storage an analysis.
Set up Amazon AppFlow
Create a new Amazon AppFlow flow to transfer data from Google Analytics to Amazon S3.
- On the Amazon AppFlow console, choose Create flow.
- Enter a name for your flow; for example,
my-bq-flow. - Add necessary Tags; for example, for Key enter
envand for Value enterdev.
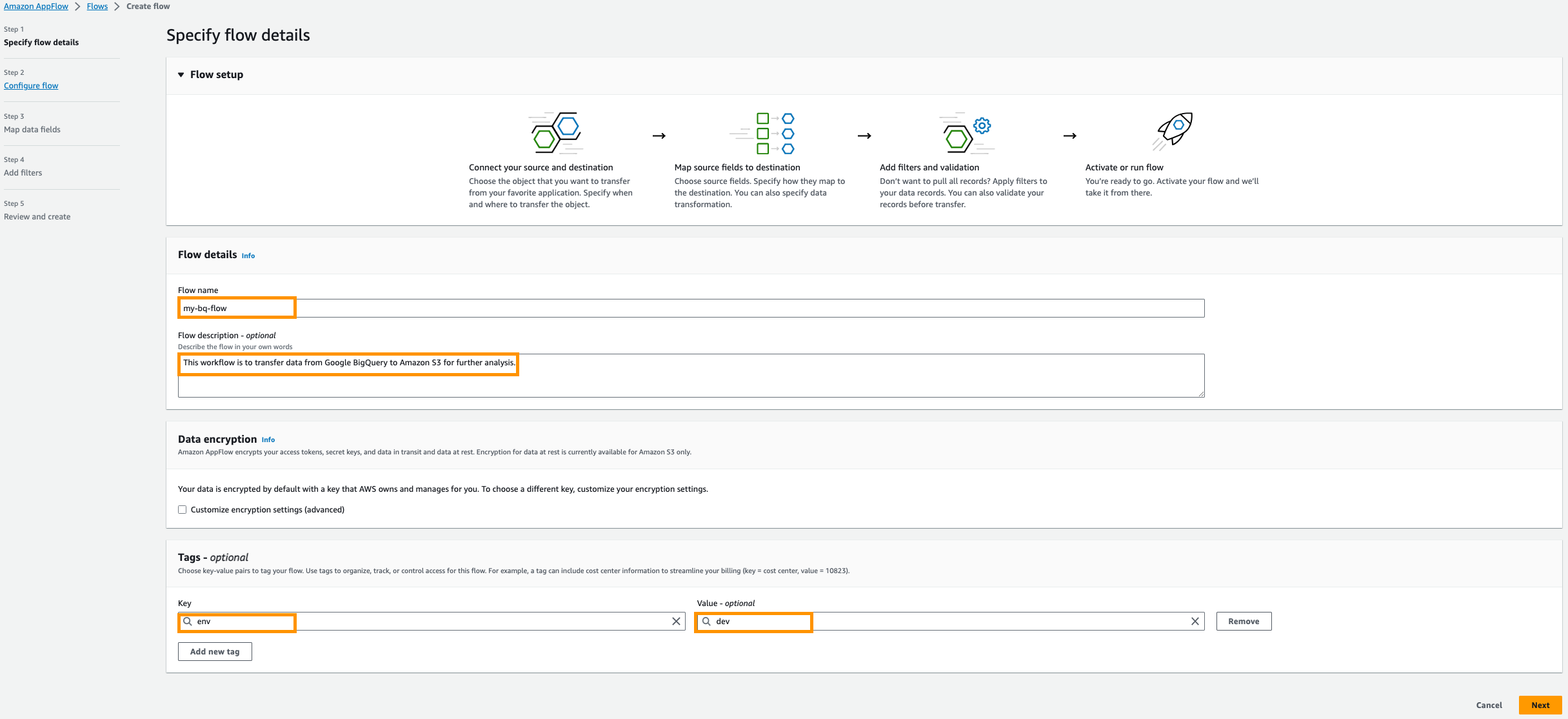
- Choose Next.
- For Source name, choose Google BigQuery.
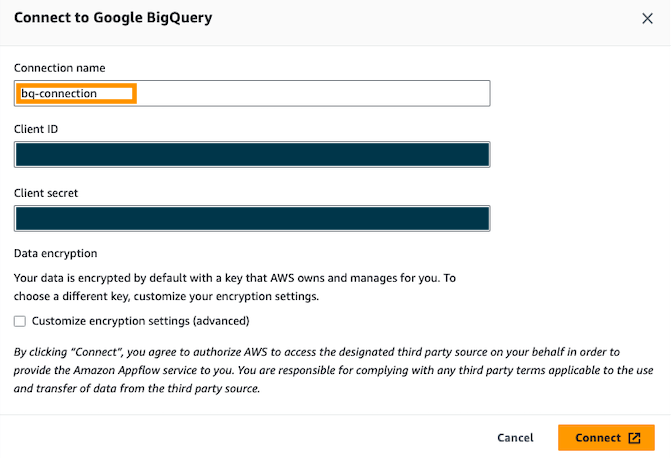
- Choose Create new connection.
- Enter your OAuth Client ID and Client Secret, then name your connection; for example,
bq-connection.
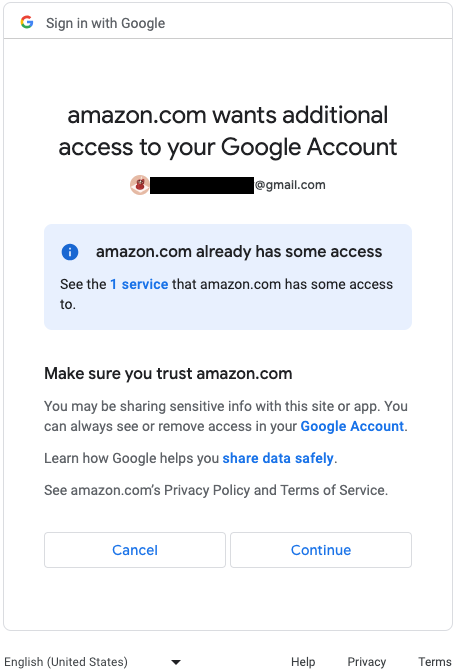
- In the pop-up window, choose to allow amazon.com access to the Google BigQuery API.
- For Choose Google BigQuery object, choose Table.
- For Choose Google BigQuery subobject, choose BigQueryProjectName.
- For Choose Google BigQuery subobject, choose DatabaseName.
- For Choose Google BigQuery subobject, choose TableName.
- For Destination name, choose Amazon S3.
- For Bucket details, choose the Amazon S3 bucket you created for storing Amazon AppFlow results in the prerequisites.
- Enter
rawas a prefix.
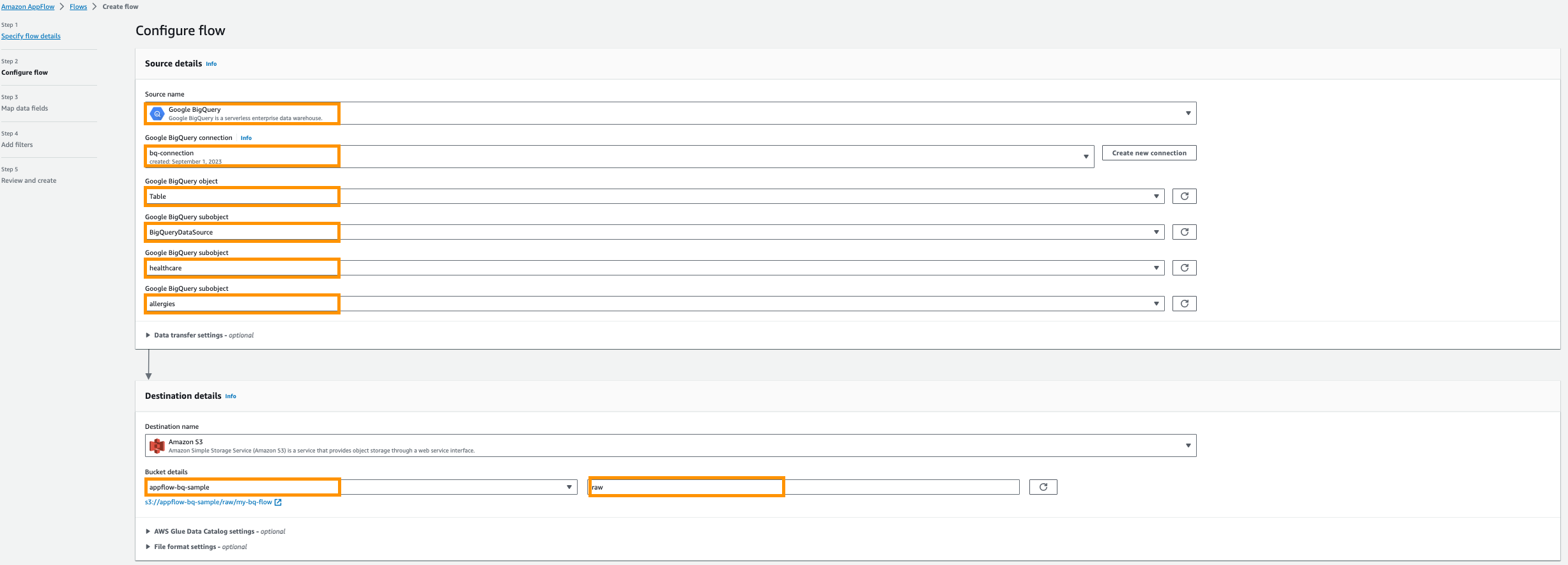
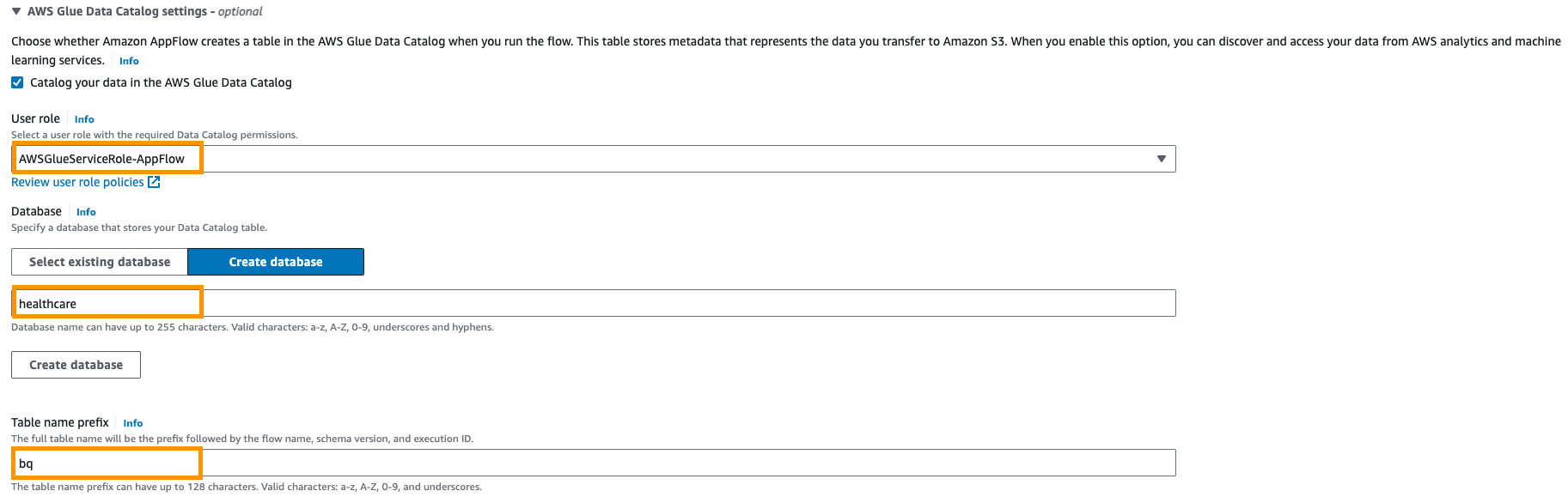
- Next, provide AWS Glue Data Catalog settings to create a table for further analysis.
- Select the User role (IAM role) created in the prerequisites.
- Create new database for example,
healthcare. - Provide a table prefix setting for example,
bq.
- Select Run on demand.
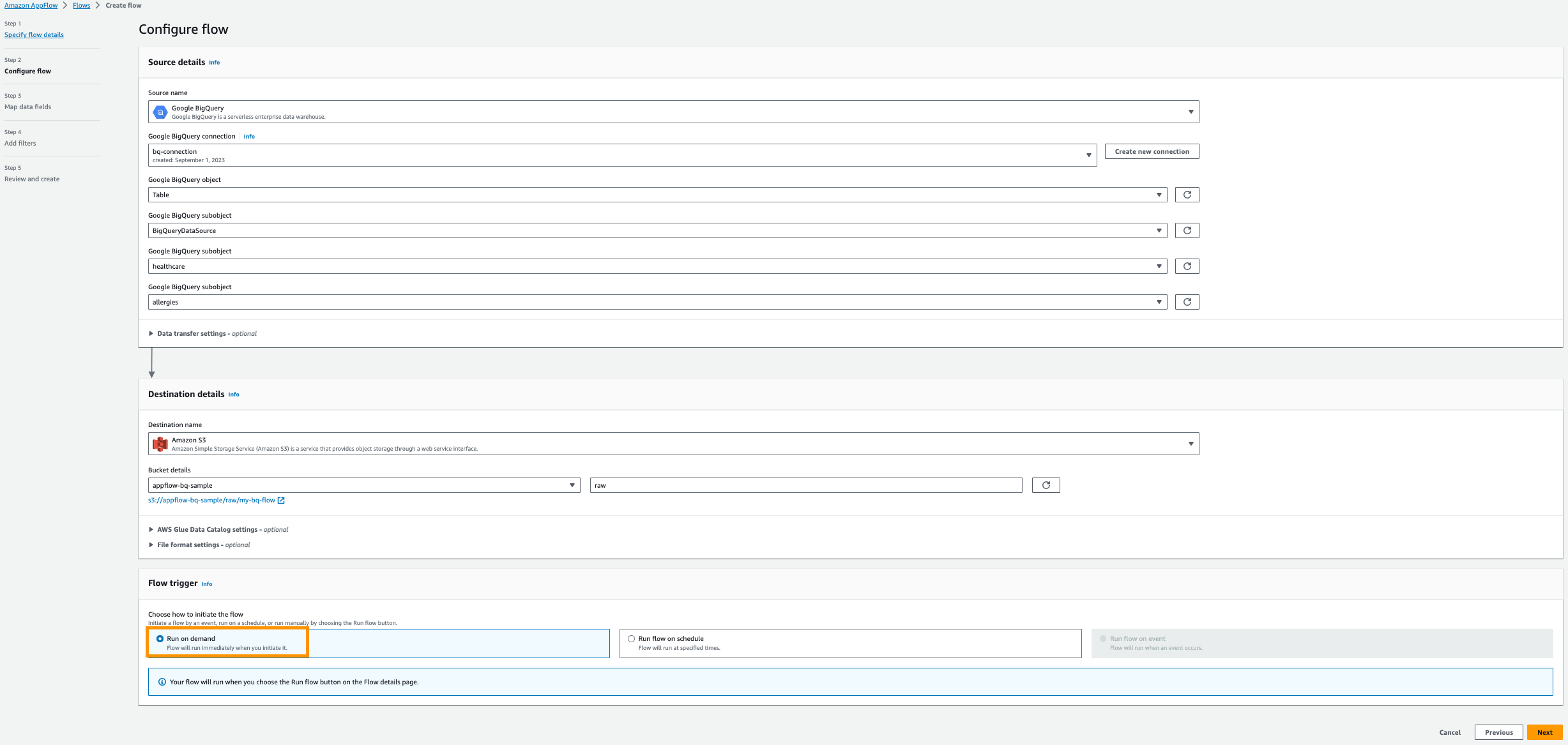
- Choose Next.
- Select Manually map fields.
- Select the following six fields for Source field name from the table Allergies:
- Start
- Patient
- Code
- Description
- Type
- Category
- Choose Map fields directly.
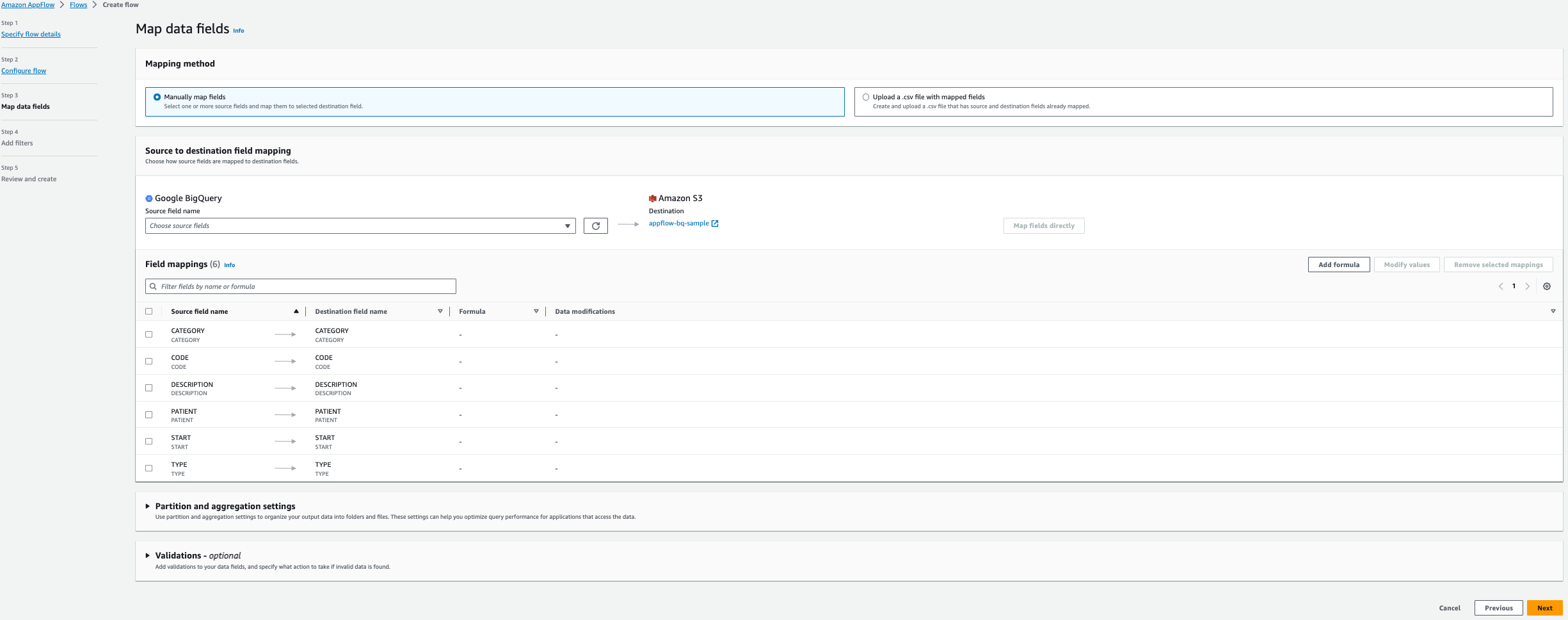
- Choose Next.
- In the Add filters section, choose Next.
- Choose Create flow.
Run the flow
After creating your new flow, you can run it on demand.
- On the Amazon AppFlow console, choose
my-bq-flow. - Choose Run flow.

For this walkthrough, choose run the job on-demand for ease of understanding. In practice, you can choose a scheduled job and periodically extract only newly added data.
Query through Amazon Athena
When you select the optional AWS Glue Data Catalog settings, Data Catalog creates the catalog for the data, allowing Amazon Athena to perform queries.
If you’re prompted to configure a query results location, navigate to the Settings tab and choose Manage. Under Manage settings, choose the Athena results bucket created in prerequisites and choose Save.
- On the Amazon Athena console, select the Data Source as
AWSDataCatalog. - Next, select Database as
healthcare. - Now you can select the table created by the AWS Glue crawler and preview it.
- You can also run a custom query to find the top 10 allergies as shown in the following query.
Note: In the below query, replace the table name, in this case bq_appflow_mybqflow_1693588670_latest, with the name of the table generated in your AWS account.
- Choose Run query.
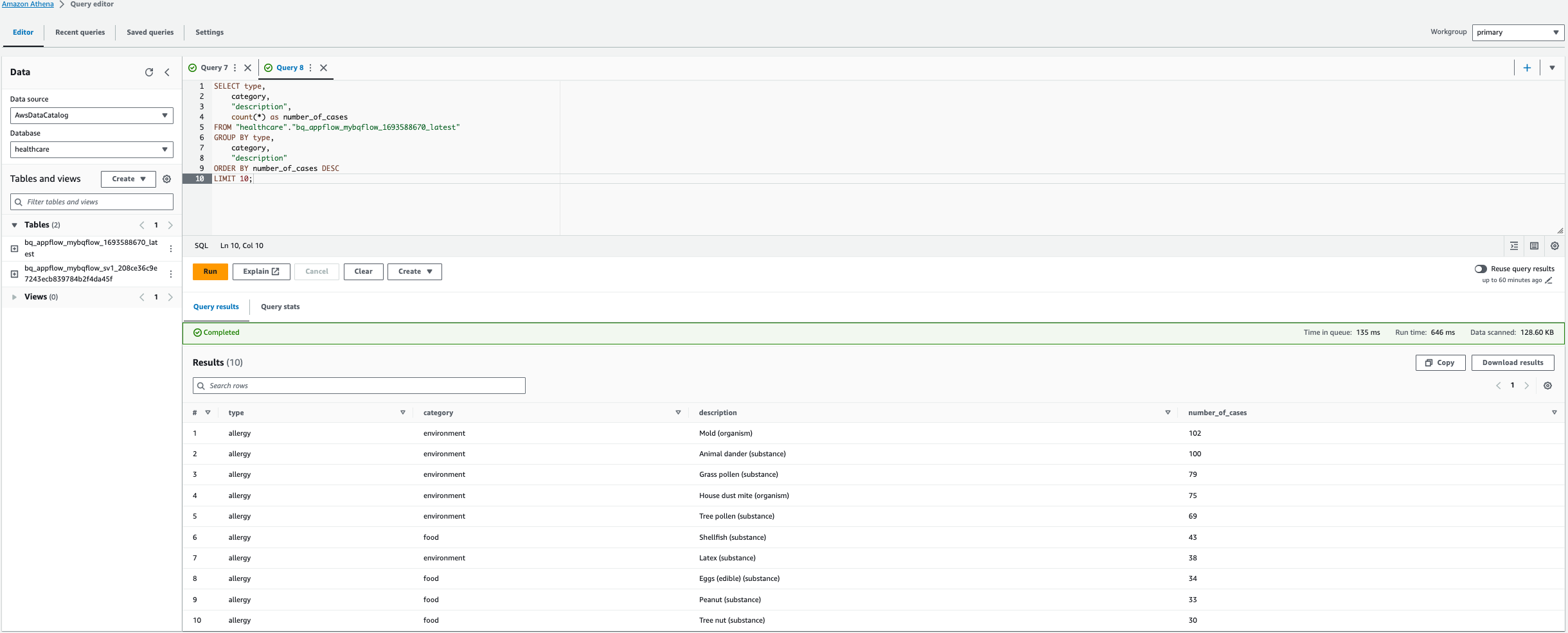
This result shows the top 10 allergies by number of cases.
Clean up
To avoid incurring charges, clean up the resources in your AWS account by completing the following steps:
- On the Amazon AppFlow console, choose Flows in the navigation pane.
- From the list of flows, select the flow
my-bq-flow, and delete it. - Enter delete to delete the flow.
- Choose Connections in the navigation pane.
- Choose Google BigQuery from the list of connectors, select
bq-connector, and delete it. - Enter delete to delete the connector.
- On the IAM console, choose Roles in the navigation page, then select the role you created for AWS Glue crawler and delete it.
- On the Amazon Athena console:
- Delete the tables created under the database
healthcareusing AWS Glue crawler. - Drop the database
healthcare
- Delete the tables created under the database
- On the Amazon S3 console, search for the Amazon AppFlow results bucket you created, choose Empty to delete the objects, then delete the bucket.
- On the Amazon S3 console, search for the Amazon Athena results bucket you created, choose Empty to delete the objects, then delete the bucket.
- Clean up resources in your Google account by deleting the project that contains the Google BigQuery resources. Follow the documentation to clean up the Google resources.
Conclusion
The Google BigQuery connector in Amazon AppFlow streamlines the process of transferring data from Google’s data warehouse to Amazon S3. This integration simplifies analytics and machine learning, archiving, and long-term storage, providing significant benefits for data professionals and organizations seeking to harness the analytical capabilities of both platforms.
With Amazon AppFlow, the complexities of data integration are eliminated, enabling you to focus on deriving actionable insights from your data. Whether you’re archiving historical data, performing complex analytics, or preparing data for machine learning, this connector simplifies the process, making it accessible to a broader range of data professionals.
If you’re interested to see how the data transfer from Google BigQuery to Amazon S3 using Amazon AppFlow, take a look at step-by-step video tutorial. In this tutorial, we walk through the entire process, from setting up the connection to running the data transfer flow. For more information on Amazon AppFlow, visit Amazon AppFlow.
About the authors
![]() Kartikay Khator is a Solutions Architect on the Global Life Science at Amazon Web Services. He is passionate about helping customers on their cloud journey with focus on AWS analytics services. He is an avid runner and enjoys hiking.
Kartikay Khator is a Solutions Architect on the Global Life Science at Amazon Web Services. He is passionate about helping customers on their cloud journey with focus on AWS analytics services. He is an avid runner and enjoys hiking.
 Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding.
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect and Amazon AppFlow expert. He’s on a mission to make life easier for customers who are facing complex data integration challenges. His secret weapon? Fully managed, low-code AWS services that can get the job done with minimal effort and no coding.
