Amazon OpenSearch Serverless is the serverless option for Amazon OpenSearch Service that makes it simple for you to run search and analytics workloads without having to think about infrastructure management. We recently announced new enhancements to autoscaling in OpenSearch Serverless that scales capacity automatically in response to your query loads.
At launch, OpenSearch Serverless supported increasing capacity automatically in response to growing data sizes. With the new shard replica scaling feature, OpenSearch Serverless automatically detects shards under duress due to sudden spikes in query rates and dynamically adds new shard replicas to handle the increased query throughput while maintaining fast response times. This approach proves to be more cost-efficient than simply adding new index replicas. With the expanded support for more replicas, OpenSearch Serverless can now handle thousands of query transactions per minute. OpenSearch Serverless will also seamlessly scale the shard replicas back to a minimum of two active replicas across the Availability Zones when the workload demand decreases.
Scaling overview
Consider an ecommerce website that uses OpenSearch Serverless as a backend search engine to host its product catalog.
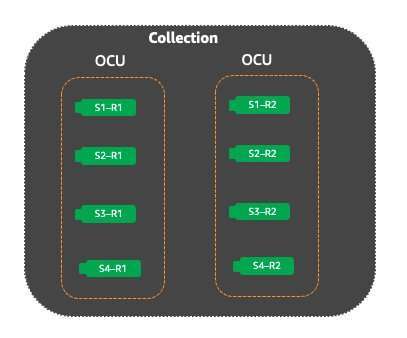 |
In the following figure, an index has four shards to handle the product catalog. All four shards fit into one OpenSearch Capacity Unit (OCU). Because OpenSearch Serverless is designed to cater to production systems, it will automatically create an additional set of replicas for these four shards, which are hosted in a separate Availability Zone. Both sets of search replicas will actively respond to the incoming traffic load. |
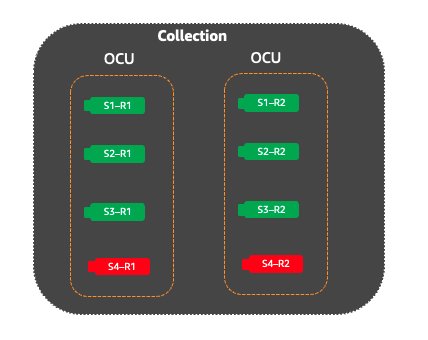 |
When new products are launched, they often generate more interest, resulting in increased traffic and search queries on the website in the days following the launch. In this scenario, the shards containing the data for the new product will receive significantly higher volume of search requests than other shards within the same index. OpenSearch Serverless will identify these shards as hot shards because they’re close to breaching the system thresholds. |
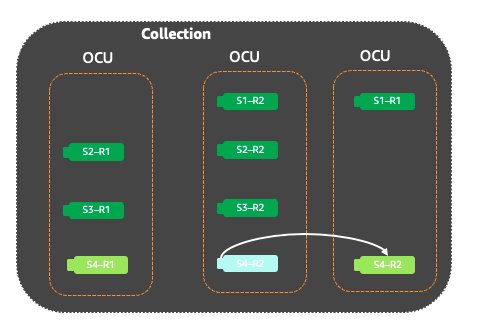 |
To handle the spike in search requests, OpenSearch Serverless will vertically scale the OCUs and then move the hot shards to a new OCU if required to balance the high query rates. The following figure shows how the shards would be moved to a new OCU along with other normally loaded shards. |
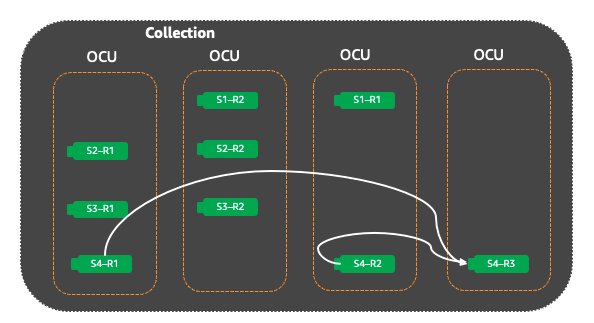 |
If OpenSearch Serverless keeps receiving additional search requests for shards, it will add new replicas for the shard until all shard replicas can effectively handle the incoming query rates without exceeding the system thresholds. Even after the traffic is successfully handled by OpenSearch Serverless, it continues to evaluate the shard state. When the load on the shards reduces, OpenSearch Serverless will scale down the shard replicas to maintain the minimum OCU and replicas required for the workload. |
Search performance with replica scale-out
We ran a performance test on a search corpus representing a product catalog with 600,000 documents and approximately 500 MB. The queries were a mix of term, fuzzy, and aggregation queries. OpenSearch Serverless was able to handle 613 transactions per second (TPS) with P50 latency of 2.8 seconds, whereas with replica scaling, we saw the search throughput scale to 1423 TPS with a 100% increase in throughput and P50 latency of 690 milliseconds, leading to a 75% improvement in response times. The following table summarizes our results. Note that you can configure the max OCU limit to control your costs.
| . | Initial OCUs | Scaled OCUs | TPS | P50 Latency | Number of Replicas |
| With no replica scaling | 2 | 26 | 613 | 2.8 secs | 2 |
| With replica scaling | 2 | 100 | 1423 | 619ms | Replica scaling scales the hot shards up to 8 replicas |
The following graphs show that under the same load profile, the new autoscaling feature handled a higher number of queries in the period of 24 hours while consistently maintaining lower latency.
The first graph shows the system performance profile without auto scaling.
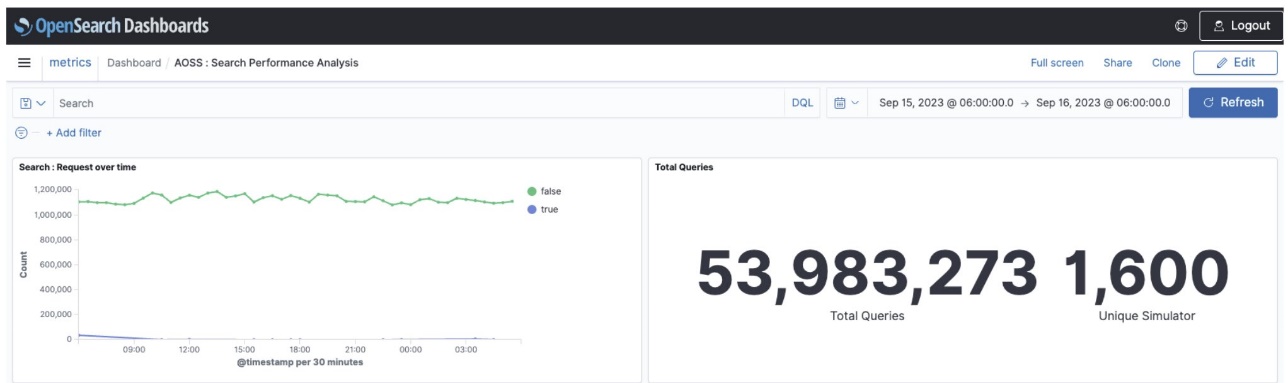
The second graph shows the system performance profile with replica scaling.
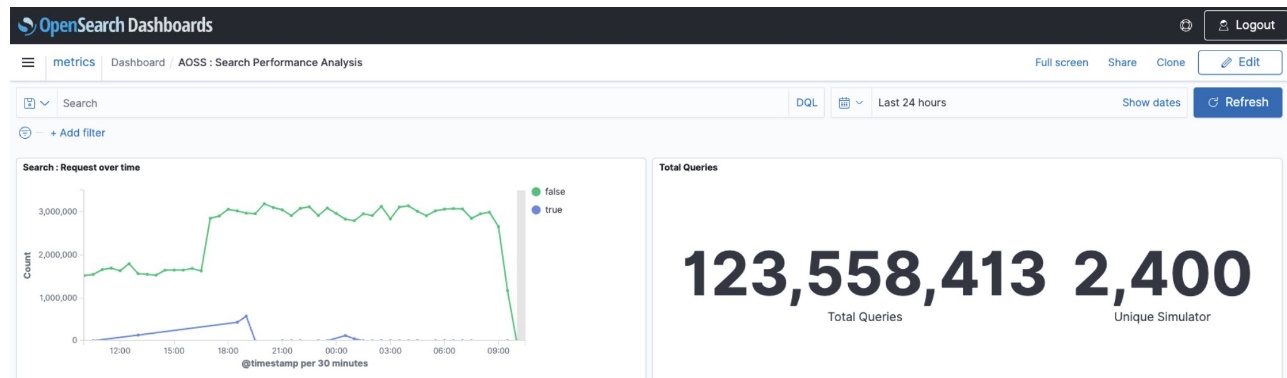
Conclusion
In this post, we showed how the OpenSearch Serverless new shard replica scale-out feature for auto scaling helps you achieve higher throughput while maintaining cost-efficiency for search and time series collections. It automatically scales the replicas for those shards under duress instead of adding replicas for the entire index.
If you have feedback about this post, share it in the comments section. If you have questions about this post, start a new thread on the Amazon OpenSearch Service forum or contact AWS Support.
About the Authors
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
 Satish Nandi is a Senior Technical Product Manager for Amazon OpenSearch Service.
Satish Nandi is a Senior Technical Product Manager for Amazon OpenSearch Service.
 Pavani Baddepudi is a Principal Product Manager working in search services at AWS. Her interests include distributed systems, networking, and security.
Pavani Baddepudi is a Principal Product Manager working in search services at AWS. Her interests include distributed systems, networking, and security.
