Today, we announce the availability of sample notebooks that demonstrate question answering tasks using a Retrieval Augmented Generation (RAG)-based approach with large language models (LLMs) in Amazon SageMaker JumpStart. Text generation using RAG with LLMs enables you to generate domain-specific text outputs by supplying specific external data as part of the context fed to LLMs.
JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. JumpStart provides many pre-trained language models called foundation models that can help you perform tasks such as article summarization, question answering, and conversation generation and image generation.
In this post, we describe RAG and its advantages, and demonstrate how to quickly get started by using a sample notebook to solve a question answering task using RAG implementation with LLMs in Jumpstart. We demonstrate two approaches:
- How to solve the problem with the open-sourced LangChain library and Amazon SageMaker endpoints in a few lines of code
- How to use the SageMaker KNN algorithm to perform semantic searching for large-scale data using SageMaker endpoints
LLMS and constraints
LLMs are trained on large amounts of unstructured data and are great at general text generation. LLMs can store factual knowledge by training their parameters on a large corpus of natural language data.
There are a few limitations of using off-the-shelf pre-trained LLMs:
- They’re usually trained offline, making the model agnostic to the latest information (for example, a chatbot trained from 2011–2018 has no information about COVID-19).
- They make predictions by only looking up information stored in its parameters, leading to inferior interpretability.
- They’re mostly trained on general domain corpora, making them less effective on domain-specific tasks. There are scenarios when you want models to generate text based on specific data rather than generic data. For example, a health insurance company may want their question answering bot to answer questions using the latest information stored in their enterprise document repository or database, so the answers are accurate and reflect their unique business rules.
Currently, there are two popular ways to reference specific data in LLMs:
- Insert data as context in the model prompt as a way to provide the information that the model can use while creating the result
- Fine-tine the model by providing a file with prompt and completion pairs
The challenge of the context-based approach is that models come with limited context size, and including all the documents as context may not fit into the allowed context size of the model. Depending on the model used, there may also be additional cost for larger context.
For the approach of fine-tuning, generating the right formatted information is time consuming and involves cost. In addition, if external data used for fine-tuning changes frequently, it would imply frequent fine-tunings and retraining are needed to create accurate results. Frequent training impacts speed to market and adds to the overall solution cost.
To demonstrate these constraints, we used an LLM Flan T5 XXL model and asked the following question:
We get the following response:
As you can see, the response is not accurate. The correct answer should be all SageMaker instances support Managed Spot Training.
We tried the same question but with additional context passed along with the question:
We got the following response this time:
The response is better but still not accurate. However, in real production use cases, users may send various queries, and to provide accurate responses, you may want to include all or most of the available information as part of the static context to create accurate responses. Therefore, with this approach, we may hit the context size limitation constraint because even non-relevant information for the question asked is sent as part of the context. This is where you can use the RAG-based approach to create scalable and accurate responses for a user’s queries.
Retrieval Augmented Generation
To solve the constraints we discussed, we can use Retrieval Augmented Generation (RAG) with LLMs. RAG retrieves data from outside the language model (non-parametric) and augments the prompts by adding the relevant retrieved data in context. RAG models were introduced by Lewis et al. in 2020 as a model where parametric memory is a pre-trained seq2seq model and the non-parametric memory is a dense vector index of Wikipedia, accessed with a pre-trained neural retriever.
In RAG, the external data can come from multiple data sources, such as a document repository, databases, or APIs. The first step is to convert the documents and the user query in the format so they can be compared and relevancy search can be performed. To make the formats comparable for doing relevancy search, a document collection (knowledge library) and the user-submitted query are converted to numerical representation using embedding language models. The embeddings are essentially numerical representations of concept in text. Next, based on the embedding of user query, its relevant text is identified in the document collection by a similarity search in the embedding space. Then the prompt provided by the user is appended with relevant text that was searched and it’s added to the context. The prompt is now sent to the LLM and because the context has relevant external data along with the original prompt, the model output is relevant and accurate.
To maintain up-to-date information for the reference documents, you can asynchronously update the documents and update embedding representation of the documents. This way, the updated documents will be used to generate answers for future questions to provide accurate responses.
The following diagram shows the conceptual flow of using RAG with LLMs.
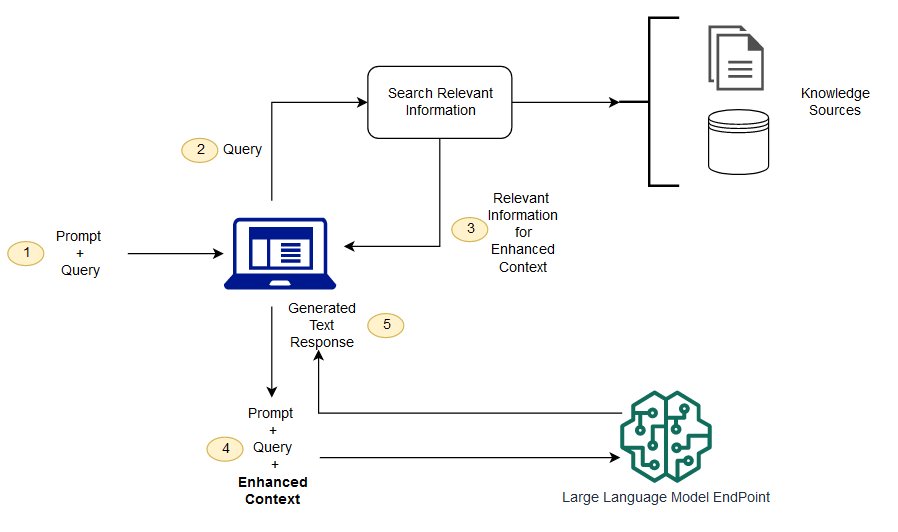
In this post, we demonstrate how to implement a question answering application with the following steps:
- Generate embedding for each of document in the knowledge library with a SageMaker GPT-J-6B embedding model.
- Identify the top K most relevant documents based on the user query.
- For your query, generate the embedding of the query using the same embedding model.
- Search the indexes of the top K most relevant documents in the embedding space using an in-memory FAISS search.
- Use the indexes to retrieve the corresponding documents.
- Use the retrieved relevant documents as context with the prompt and question, and send them to the SageMaker LLM to generate the response.
We demonstrate the following approaches:
- How to solve a question answering task with SageMaker LLMs and embedding endpoints and the open-sourced library LangChain in a few lines of code. In particular, we use two SageMaker endpoints for the LLM (Flan T5 XXL) and embedding model (GPT-J 6B), and the vector database used is in-memory FAISS. For more details, see the GitHub repo.
- If the in-memory FAISS doesn’t fit into your large dataset, we provide you with a SageMaker KNN algorithm to perform the semantic search, which also uses FAISS as the underlying searching algorithm. For details, see the GitHub repo.
The following diagram depicts the solution architecture.

JumpStart RAG-based implementation notebook with LangChain
LangChain is an open-source framework for developing applications powered by language models. LangChain provides a generic interface for many different LLMs. It also makes it easier for developers to chain various LLMs together and build powerful applications. LangChain provides a standard interface for memory and a collection of memory implementations to persist the state between calls of agents or chains.
LangChain has many other utility features that can add to developer productivity. These features include a prompt template that helps customize prompts using variables in the prompt template, agents to build end-to-end applications, indexes for search and retrieval steps of the chain, and much more. To further explore LangChain capabilities, refer to the LangChain documentation.
Create LLM Model
As a first step, deploy the JumpStart LLM model of your choice. In this demo, we use a Jumpstart Flan T5 XXL model endpoint. For deployment instructions, refer to Zero-shot prompting for the Flan-T5 foundation model in Amazon SageMaker JumpStart. Based on your use case, you can also deploy other instruction-tuned models like Flan T5 UL2 or BloomZ 7B1. For details, see the example notebook.
To use the SageMaker LLM endpoint with LangChain, we use langchain.llms.sagemaker_endpoint.SagemakerEndpoint, which abstracts the SageMaker LLM endpoint. We need to perform a transformation for the request and response payload as shown in the following code for the LangChain SageMaker integration. Note that you may need to adjust the code in ContentHandler based on the content_type and accepts format of the LLM model that you choose to use.
Create the embedding model
Next, we need to get our embedded model ready. We deploy the GPT-J 6B model as the embedding model. If you’re using a JumpStart embedding model, you need to customize the LangChain SageMaker endpoint embedding class and transform the model request and response to integrate with LangChain. For a detailed implementation, refer to the GitHub repo.
Load domain-specific documents using the LangChain document loader and create an index
We use the CSVLoader package in LangChain to load CSV-formatted documents into the document loader:
Next, we use TextSplitter to preprocess data for embedding purposes and use the SageMaker embedding model GPT-J -6B to create the embedding. We store embedding in a FAISS vector store to create an index. We use this index to find relevant documents that are semantically similar to the user’s query.
The following code shows how all these steps are done by the VectorstoreIndexCreator class in just few lines of code in LangChain to create a concise implementation of question answering with RAG:
Use the index to search for relevant context and pass it to the LLM model
Next, use the query method on the created index and pass the user’s question and SageMaker endpoint LLM. LangChain selects the top four closest documents (K=4) and passes the relevant context extracted from the documents to generate an accurate response. See the following code:
We get the following response for the query using the RAG-based approach with Flan T5 XXL:
The response looks more accurate compared to the response we got with other approaches that we demonstrated earlier that have no context or static context that may not be always relevant.
Alternate approach to implement RAG with more customization using SageMaker and LangChain
In this section, we show you another approach to implement RAG using SageMaker and LangChain. This approach offers the flexibility to configure top K parameters for a relevancy search in the documents. It also allows you to use the LangChain feature of prompt templates, which allow you to easily parameterize the prompt creation instead of hard coding the prompts.
In the following code, we explicitly use FAISS to generate embedding for each of the document in the knowledge library with the SageMaker GPT-J-6B embedding model. Then we identify the top K (K=3) most relevant documents based on the user query.
Next, we use a prompt template and chain it with the SageMaker LLM:
We send the top three (K=3) relevant documents we found as context to the prompt by using a LangChain chain:
With this approach of RAG implementation, we were able to take advantage of the additional flexibility of LangChain prompt templates and customize the number of documents searched for a relevancy match using the top K hyperparameter.
JumpStart RAG-based implementation notebook with SageMaker KNN
In this section, we implement the RAG-based approach using the KNN algorithm for finding relevant documents to create enhanced context. In this approach, we’re not using LangChain, but we use same dataset Amazon SageMaker FAQs as knowledge documents, embedding the models GPT-J-6B and LLM Flan T5 XXL just as we did in the previous LangChain approach.
If you have a large dataset, the SageMaker KNN algorithm may provide you with an effective semantic search. The SageMaker KNN algorithm also uses FAISS as the underlying search algorithm. The notebook for this solution can be found on GitHub.
First, we deploy the LLM Flan T5 XXL and GPT-J 6B embedding models in the same way as in the previous section. For each record in the knowledge database, we generate an embedding vector using the GPT-J embedding model.
Next, we use a SageMaker KNN training job to index the embedding of the knowledge data. The underlying algorithm used to index the data is FAISS. We want to find the top five most relevant documents, so we set the TOP_K variable to 5. We create the estimator for the KNN algorithm, run the training job, and deploy the KNN model to find indexes of the top five documents matching the query. See the following code:
Next, we create an embedding representation of the query using the GPT-J-6B embedding model that we used for creating an embedding of the knowledge library documents:
Then we use the KNN endpoint and pass the embedding of the query to the KNN endpoint to get the indexes of the top K most relevant documents. We use the indexes to retrieve the corresponded textual documents. Next, we concatenate the documents, ensuring the maximum allowed length of context is not exceeded. See the following code:
Now we come to our final step in which we combine the query, prompt, and the context containing text from relevant documents and pass it to the text generation LLM Flan T5 XXL model to generate the answer.
We get the following response for the query using a RAG-based approach with Flan T5 XXL:
Clean up
Make sure to delete the endpoints that we created in this notebook when not using them to avoid reoccurring cost.
Conclusion
In this post, we demonstrated the implementation of a RAG-based approach with LLMs for question answering tasks using two approaches: LangChain and the built-in KNN algorithm. The RAG-based approach optimizes the accuracy of the text generation using Flan T5 XXL by dynamically providing relevant context that was created by searching a list of documents.
You can use this these notebooks in SageMaker as is or you may customize them to your needs. To customize, you can use your own set of documents in the knowledge library, use other relevancy search implementations like OpenSearch, and use other embedding models and text generation LLMs available on JumpStart.
We look forward to seeing what you build on JumpStart using a RAG-based approach!
About the authors
 Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
Dr. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on developing scalable machine learning algorithms. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A.
 Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economical and social prosperity. In her spare time, Rachna likes spending time with her family, hiking and listening to music.
Rachna Chadha is a Principal Solution Architect AI/ML in Strategic Accounts at AWS. Rachna is an optimist who believes that ethical and responsible use of AI can improve society in future and bring economical and social prosperity. In her spare time, Rachna likes spending time with her family, hiking and listening to music.
 Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
Dr. Kyle Ulrich is an Applied Scientist with the Amazon SageMaker built-in algorithms team. His research interests include scalable machine learning algorithms, computer vision, time series, Bayesian non-parametrics, and Gaussian processes. His PhD is from Duke University and he has published papers in NeurIPS, Cell, and Neuron.
 Hemant Singh is a Machine Learning Engineer with experience in Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He had experience in working on a diverse range of Machine Learning problems within the domain of natural language processing, computer vision, and time-series analysis.
Hemant Singh is a Machine Learning Engineer with experience in Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He got his masters from Courant Institute of Mathematical Sciences and B.Tech from IIT Delhi. He had experience in working on a diverse range of Machine Learning problems within the domain of natural language processing, computer vision, and time-series analysis.
 Manas Dadarkar is a Software Development Manager owning the engineering of the Amazon Forecast service. He is passionate about the applications of machine learning and making ML technologies easily available for everyone to adopt and deploy to production. Outside of work, he has multiple interests including travelling, reading and spending time with friends and family.
Manas Dadarkar is a Software Development Manager owning the engineering of the Amazon Forecast service. He is passionate about the applications of machine learning and making ML technologies easily available for everyone to adopt and deploy to production. Outside of work, he has multiple interests including travelling, reading and spending time with friends and family.
 Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
Dr. Ashish Khetan is a Senior Applied Scientist with Amazon SageMaker built-in algorithms and helps develop machine learning algorithms. He got his PhD from University of Illinois Urbana-Champaign. He is an active researcher in machine learning and statistical inference, and has published many papers in NeurIPS, ICML, ICLR, JMLR, ACL, and EMNLP conferences.
