Amazon EMR Serverless provides a serverless runtime environment that simplifies the operation of analytics applications that use the latest open source frameworks, such as Apache Spark and Apache Hive. With EMR Serverless, you don’t have to configure, optimize, secure, or operate clusters to run applications with these frameworks. You can run analytics workloads at any scale with automatic scaling that resizes resources in seconds to meet changing data volumes and processing requirements. EMR Serverless automatically scales resources up and down to provide just the right amount of capacity for your application, and you only pay for what you use.
AWS Step Functions is a serverless orchestration service that enables developers to build visual workflows for applications as a series of event-driven steps. Step Functions ensures that the steps in the serverless workflow are followed reliably, that the information is passed between stages, and errors are handled automatically.
The integration between AWS Step Functions and Amazon EMR Serverless makes it easier to manage and orchestrate big data workflows. Before this integration, you had to manually poll for job statuses or implement waiting mechanisms through API calls. Now, with the support for “Run a Job (.sync)” integration, you can more efficiently manage your EMR Serverless jobs. Using .sync allows your Step Functions workflow to wait for the EMR Serverless job to complete before moving on to the next step, effectively making job execution part of your state machine. Similarly, the “Request Response” pattern can be useful for triggering a job and immediately getting a response back, all within the confines of your Step Functions workflow. This integration simplifies your architecture by eliminating the need for additional steps to monitor job status, making the whole system more efficient and easier to manage.
In this post, we explain how you can orchestrate a PySpark application using Amazon EMR Serverless and AWS Step Functions. We run a Spark job on EMR Serverless that processes Citi Bike dataset data in an Amazon Simple Storage Service (Amazon S3) bucket and stores the aggregated results in Amazon S3.
Solution Overview
We demonstrate this solution with an example using the Citi Bike dataset. This dataset includes numerous parameters such as Rideable type, Start station, Started at, End station, Ended at, and various other elements about Citi Bikers ride. Our objective is to find the minimum, maximum, and average bike trip duration in a given month.
In this solution, the input data is read from the S3 input path, transformations and aggregations are applied with the PySpark code, and the summarized output is written to the S3 output path s3://<bucket-name>/serverlessout/.
The solution is implemented as follows:
- Creates an EMR Serverless application with Spark runtime. After the application is created, you can submit the data-processing jobs to that application. This API step waits for Application creation to complete.
- Submits the PySpark job and waits for its completion with the
StartJobRun(.sync) API. This allows you to submit a job to an Amazon EMR Serverless application and wait until the job completes. - After the PySpark job completes, the summarized output is available in the S3 output directory.
- If the job encounters an error, the state machine workflow will indicate a failure. You can inspect the specific error within the state machine. For a more detailed analysis, you can also check the EMR job failure logs in the EMR studio console.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- An AWS account
- An IAM user with administrator access
- An S3 bucket
Solution Architecture
To automate the complete process, we use the following architecture, which integrates Step Functions for orchestration and Amazon EMR Serverless for data transformations. Summarized output is then written to Amazon S3 bucket.
The following diagram illustrates the architecture for this use case
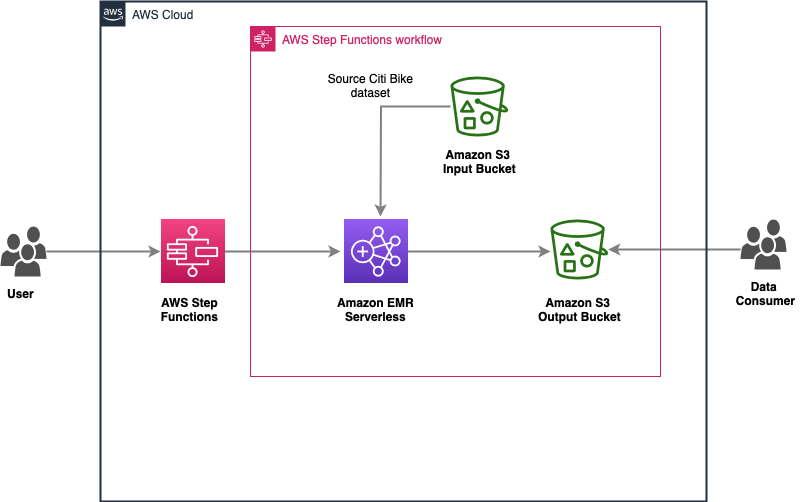
Deployment steps
Before beginning this tutorial, ensure that the role being used to deploy has all the relevant permissions to create the required resources as part of the solution. The roles with the appropriate permissions will be created through a CloudFormation template using the following steps.
Step 1: Create a Step Functions state machine
You can create a Step Functions State Machine workflow in two ways— either through the code directly or through the Step Functions studio graphical interface. To create a state machine, you can follow the steps from either option 1 or option 2 below.
Option 1: Create the state machine through code directly
To create a Step Functions state machine along with the necessary IAM roles, complete the following steps:
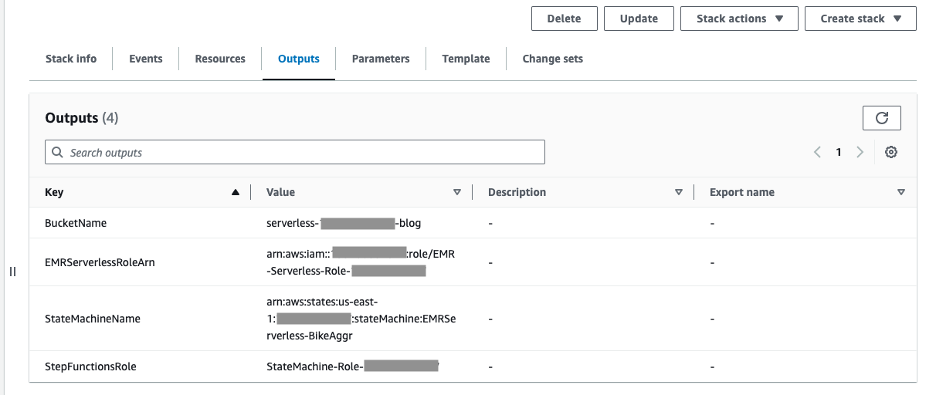
- Launch the CloudFormation stack using this link. On the Cloud Formation console, provide a stack name and accept the defaults to create the stack. Once the CloudFormation deployment completes, the following resources are created, in addition EMR Service Linked Role will be automatically created by this CloudFormation stack to access EMR Serverless:
- S3 bucket to upload the PySpark script and write output data from EMR Serverless job. We recommend enabling default encryption on your S3 bucket to encrypt new objects, as well as enabling access logging to log all requests made to the bucket. Following these recommendations will improve security and provide visibility into access of the bucket.
- EMR Serverless Runtime role that provides granular permissions to specific resources that are required when EMR Serverless jobs run.
- Step Functions Role to grant AWS Step Functions permissions to access the AWS resources that will be used by its state machines.
- State Machine with EMR Serverless steps.
- To prepare the S3 bucket with PySpark script, open AWS Cloudshell from the toolbar on the top right corner of AWS console and run the following AWS CLI command in CloudShell (make sure to replace <<ACCOUNT-ID>> with your AWS Account ID):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- To prepare the S3 bucket with Input data, run the following AWS CLI command in CloudShell (make sure to replace <<ACCOUNT-ID>> with your AWS Account ID):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

Option 2: Create the Step Functions state machine through Workflow Studio
Prerequisites
Before creating the State Machine though Workshop Studio, please ensure that all the relevant roles and resources are created as part of the solution.
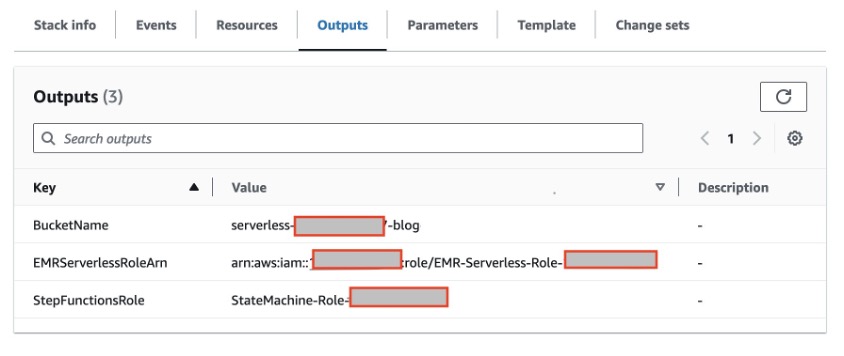
- To deploy the necessary IAM roles and S3 bucket into your AWS account, launch the CloudFormation stack using this link. Once the CloudFormation deployment completes, the following resources are created:
- S3 bucket to upload the PySpark script and write output data. We recommend enabling default encryption on your S3 bucket to encrypt new objects, as well as enabling access logging to log all requests made to the bucket. Following these recommendations will improve security and provide visibility into access of the bucket.
- EMR Serverless Runtime role that provides granular permissions to specific resources that are required when EMR Serverless jobs run.
- Step Functions Role to grant AWS Step Functions permissions to access the AWS resources that will be used by its state machines.
- To prepare the S3 bucket with PySpark script, open AWS Cloudshell from the toolbar on the top right of the AWS console and run the following AWS CLI command in CloudShell (make sure to replace <<ACCOUNT-ID>> with your AWS Account ID):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/bikeaggregator.py s3://serverless-<<ACCOUNT-ID>>-blog/scripts/
![]()

- To prepare the S3 bucket with Input data, run the following AWS CLI command in CloudShell (make sure to replace <<ACCOUNT-ID>> with your AWS Account ID):
aws s3 cp s3://aws-blogs-artifacts-public/artifacts/BDB-3594/201306-citibike-tripdata.csv s3://serverless-<<ACCOUNT-ID>>-blog/data/ --copy-props none

To create a Step Functions state machine, complete the following steps:
- On the Step Functions console, choose Create state machine.
- Keep the Blank template selected, and click Select.
- In the Actions Menu on the left, Step Functions provides a list of AWS services APIs that you can drag and drop into your workflow graph in the design canvas. Type EMR Serverless in the search and drag the Amazon EMR Serverless CreateApplication state to the workflow graph:
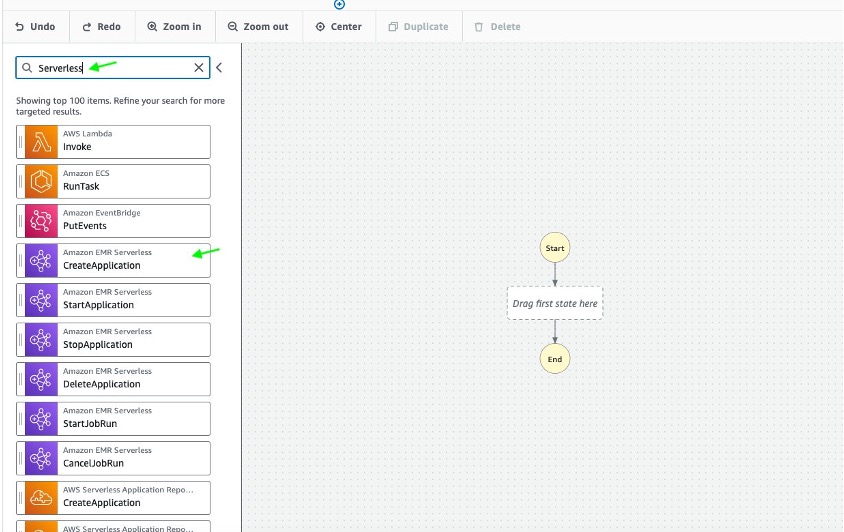
- In the canvas, select Amazon EMR Serverless CreateApplication state to configure its properties. The Inspector panel on the right shows configuration options. Provide the following Configuration values:
- Change the State name to Create EMR Serverless Application
- Provide the following values to the API Parameters. This creates an EMR Serverless Application with Apache Spark based on Amazon EMR release 6.12.0 using default configuration settings.
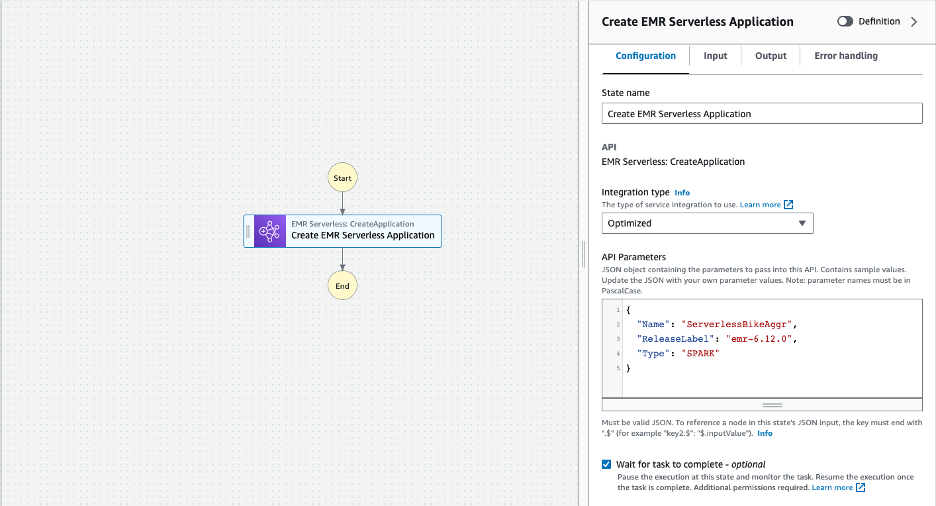
- Click the Wait for task to complete – optional check box to wait for EMR Serverless Application creation state to complete before executing the next state.
- Under Next state, select the Add new state option from the drop-down.
- Drag EMR Serverless StartJobRun state from the left browser to the next state in the workflow.
- Rename State name to Submit PySpark Job
- Provide the following values in the API parameters and click Wait for task to complete – optional (make sure to replace <<ACCOUNT-ID>> with your AWS Account ID).
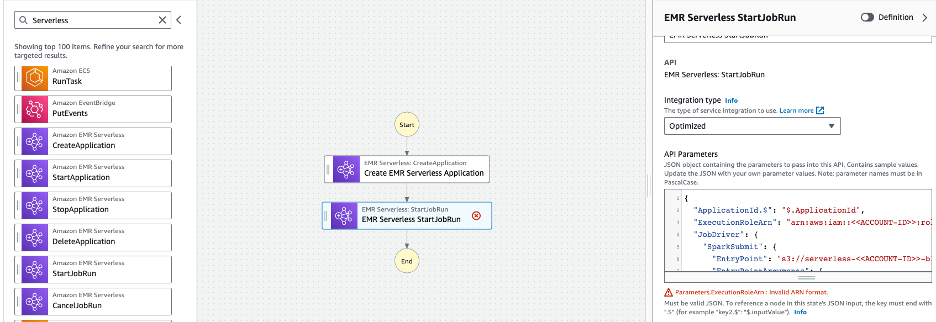
- Select the Config tab for the state machine from the top and change the following configurations:
- Change State machine name to EMRServerless-BikeAggr found in Details.
- In the Permissions section, select StateMachine-Role-<<ACCOUNT-ID>> from the dropdown for Execution role. (Make sure that you replace <<ACCOUNT-ID>> with your AWS Account ID).
- Continue to add steps for Check Job Success from the studio as shown in the following diagram.
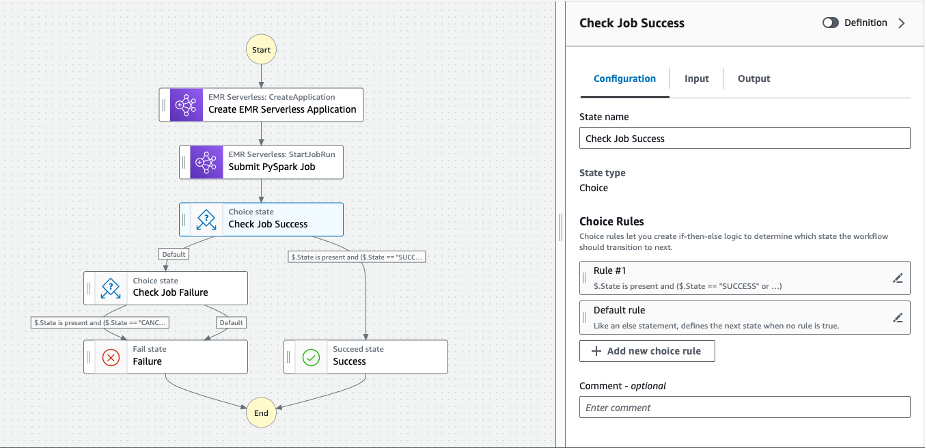
- Click Create to create the Step Functions State Machine for orchestrating the EMR Serverless jobs.
Step 2: Invoke the Step Functions
Now that the Step Function is created, we can invoke it by clicking on the Start execution button:
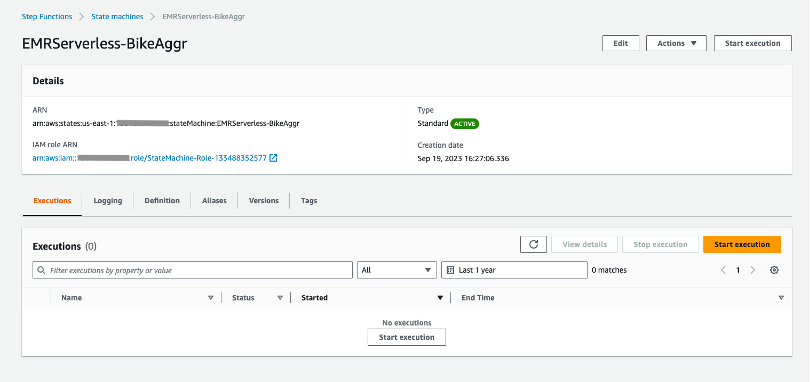
When the step function is being invoked, it presents its run flow as shown in the following screenshot. Because we have selected Wait for task to complete config (.sync API) for this step, the next step would not start wait until EMR Serverless Application is created (blue represents the Amazon EMR Serverless Application being created).
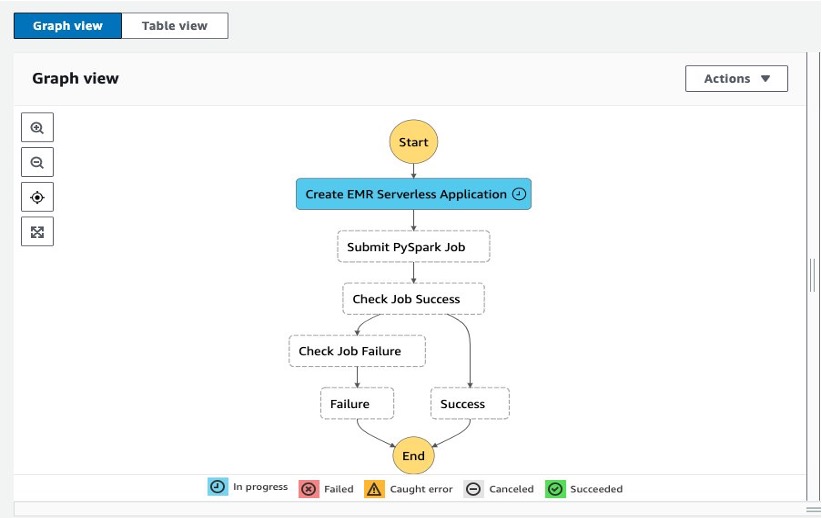
After successfully creating the EMR Serverless Application, we submit a PySpark Job to that Application.
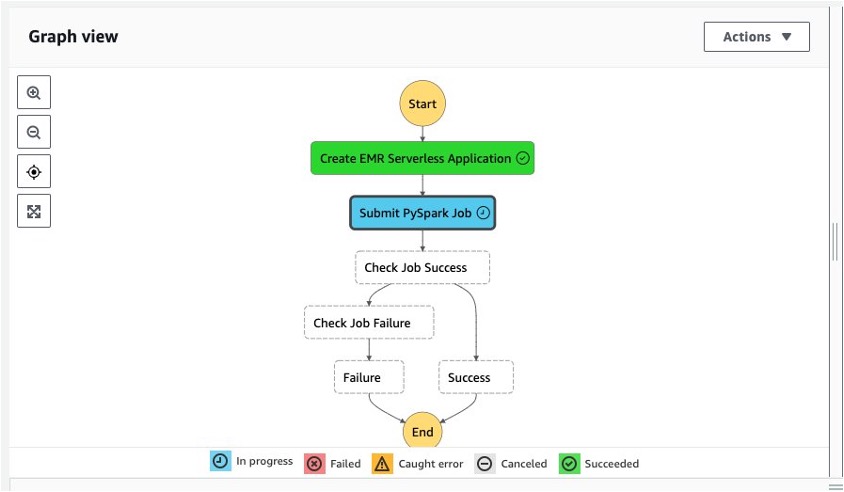
When the EMR Serverless job completes, the Submit PySpark Job step changes to green. This is because we have selected the Wait for task to complete configuration (using the .sync API) for this step.
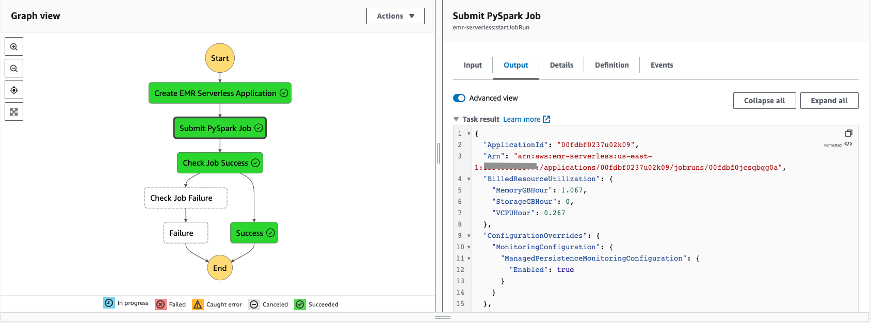
The EMR Serverless Application ID as well as PySpark Job run Id from Output tab for Submit PySpark Job step.
Step 3: Validation
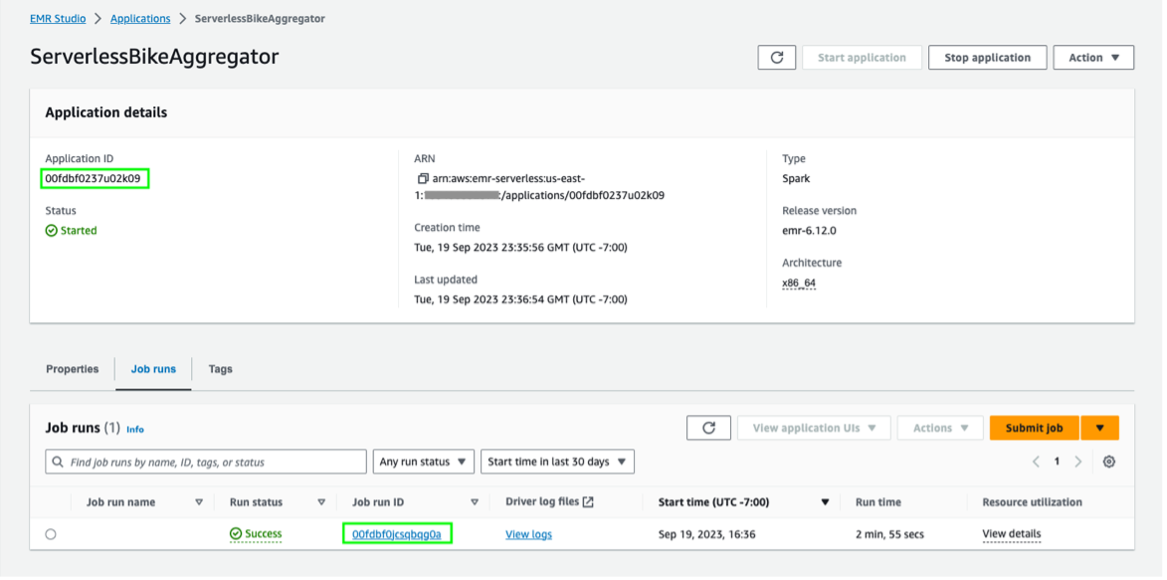
To confirm the successful completion of the job, navigate to EMR Serverless console and find the EMR Serverless Application Id. Click the Application Id to find the execution details for the PySpark Job run submitted from the Step Functions.
To verify the output of the job execution, you can check the S3 bucket where the output will be stored in a .csv file as shown in the following graphic.
Cleanup
Log in to the AWS Management Console and delete any S3 buckets created by this deployment to avoid unwanted charges to your AWS account. For example: s3://serverless-<<ACCOUNT-ID>>-blog/
Then clean up your environment, delete the CloudFormation template you created in the Solution configuration steps.
Delete Step function you created as part of this solution.
Conclusion
In this post, we explained how to launch an Amazon EMR Serverless Spark job with Step Functions using Workflow Studio to implement a simple ETL pipeline that creates aggregated output from the Citi Bike dataset and generate reports.
We hope this gives you a great starting point for using this solution with your datasets and applying more complex business rules to solve your transient cluster use cases.
Do you have follow-up questions or feedback? Leave a comment. We’d love to hear your thoughts and suggestions.
References
About the Authors
 Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, Serverless, Architecting Microservices and helping customers leverage the power of AWS cloud.
Naveen Balaraman is a Sr Cloud Application Architect at Amazon Web Services. He is passionate about Containers, Serverless, Architecting Microservices and helping customers leverage the power of AWS cloud.
 Karthik Prabhakar is a Senior Big Data Solutions Architect for Amazon EMR at AWS. He is an experienced analytics engineer working with AWS customers to provide best practices and technical advice in order to assist their success in their data journey.
Karthik Prabhakar is a Senior Big Data Solutions Architect for Amazon EMR at AWS. He is an experienced analytics engineer working with AWS customers to provide best practices and technical advice in order to assist their success in their data journey.
 Parul Saxena is a Big Data Specialist Solutions Architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue and AWS Lake Formation, where she provides architectural guidance to customers for running complex big data workloads over AWS platform. In her spare time, she enjoys traveling and spending time with her family and friends.
Parul Saxena is a Big Data Specialist Solutions Architect at Amazon Web Services, focused on Amazon EMR, Amazon Athena, AWS Glue and AWS Lake Formation, where she provides architectural guidance to customers for running complex big data workloads over AWS platform. In her spare time, she enjoys traveling and spending time with her family and friends.
