Tensor Core GPUs have created a generative AI model gold rush. Whether it’s helping students with math homework, planning a vacation, or learning to prepare a six-course meal, generative AI is ready with answers. But that’s only one aspect of AI, and not every application requires it.
AI — now an all-inclusive term, referring to the process of using algorithms to learn, predict, and make decisions — mimics human intelligence. It can take on jobs like recognizing faces and patterns and interpreting data in problem solving. Many tasks can be automated with AI to increase productivity and link together data that is either too complex for the human brain or requires too much manual effort.
But the amount of compute horsepower needed to utilize AI varies widely, depending on the application and the type of AI. Level 3 autonomous driving requires very different AI from a retail application using AI to monitor customer traffic. The more complex the task and the more accurate the results, the more AI compute power is demanded, and the more data that must be gathered to train the AI.
So how should developers go about making the right AI choice? “AI needs to learn from data,” said Dan Yu, product manager for AI/ML solutions in IC design verification at Siemens EDA, “The first question every developer needs to ask is, ‘Where can I get the data to train my AI and machine learning models?’ Third-party data may be available, but you have to validate it to make sure that it is the right data and that the AI/machine learning model makes the right prediction. If there is no data, there is no machine learning.”
It is very common for at least 70% of AI training time to be spent on finding the right data, cleaning the data, and extracting useful information from the data. Much of the balance is spent on fine tuning AI and machine learning models.
“When we talk about training, fine tuning, and deploying the AI machine learning model into the application, many leaders in autonomous driving struggle with finding enough meaningful data,” Yu said. “They may have the means to collect a lot of data from dashcams and sensors such as lidar around their car, but most data is not useful in training the AI model. You want the model to experience all the unimaginable scenarios. For example, a building just collapsed in front of your vehicle. What’s your action? As humans, we know we want to run away. It is in the human gene. But it’s not in the AI gene if that situation has not been encountered. If you don’t have data to train AI to do something, AI will just assume nothing has happened, and the autonomous vehicle will just keep driving. Data is the critical part of AI anywhere.”
AI benefits come at a price
AI’s role is growing in manufacturing, automotive, finance, health care, education, agriculture, smart cities, entertainment, defense, energy, retail, and data centers, among others. AI chips are now installed in desktops and laptops. However, all the benefits AI is bringing to numerous sectors are not free.
A Tensor Core GPU from NVIDIA can cost up to $40,000 and consume as much as 700W. For high-end applications such as scientific and language modeling, high-performance machine learning systems such as that from Cerebras would be needed. A new second generation wafer scale processor (WSE – 2) consisting of 2.6 trillion transistors and 850,000 AI-optimized compute cores with multiple redundant 4KW power supplies would cost multiple millions of dollars.
“Everyone is talking about everything generative AI can do for you, but there is a hidden cost,” said Jeff Wittich, chief product officer at Ampere. “If all we care about is running max performance, AI will quickly become the number one user of energy is the world. Already today data centers produce about 3% of the world’s CO2 — more than aviation and shipping. AI is set to require many more times compute power, and this can quickly become out of control. It can be compared to owning a race car. Sure, it can go very fast, but it requires a lot of fuel. For a race it’s okay. For everyone to drive one of those everyday would be disastrous.”
Optimization of models and increasing computational utilization are the key. “Today, many AI inference models are running on power-hungry GPUs,” Wittich said. “These GPUs are very powerful and can run models quickly, but we are increasingly seeing an under-utilization of their capabilities. Many companies don’t need all the power all the time, and GPUs are still using power while they are idle.”
Types of AI
Generative AI and predictive AI are two very different types of AI. The former requires high performance and intensive computing, while the latter can be implemented with low-cost SoCs.
“AI use cases today can be broadly classified into two areas — generative AI and predictive AI,” said Kaushal Vora, senior director and head of business, acceleration & ecosystem at Renesas Electronics. “The primary goal of generative AI is to generate new content, and the goal of predictive AI is to analyze data to make predictions and business decisions. Generative AI leverages foundation models and transformers to target broad and large-scale applications in linguistics, text, images, video, etc. These models tend to be very large, typically consuming hundreds of gigabytes of memory and requiring ultra-large-scale compute in the form of GPUs and CPUs in the cloud to train and run inference on.”
Predictive AI, in contrast, runs on more resource-constrained layers of the network, like the network edge and the IoT endpoints. “This type of AI is also commonly referred to as Edge AI or TinyML,” Vora said. “Some of the areas and use cases at the edge/endpoint that are seeing rapid AI adoption are voice as a user interface for human-to-machine communication, environmental sensing and predictive analytics, and maintenance of machines. We see adoption across a broad range of industry verticals. The compute engine running this AI is typically a microcontroller with a few GOPS (giga-operations per second), or a microprocessor with sub-1 TOPS of performance.”
At the same time, generative AI is driving demands for extremely high AI performance at the server level. Gordon Cooper, product manager, AI/ML processors at Synopsys, said the key performance indicators (KPIs) at that level relate to performance, meaning how long someone will have to wait for generative AI to spit out an answer, and to area and power/thermal costs. “The only real-time application requiring significant generative AI (1,000+ TOPS) is L3/L4 autonomous driving. Given the excitement and hype about generative AI, lots of questions are being asked on how best to move those capabilities to edge devices. Algorithms will have to evolve. There are too many parameters required for something like ChatGPT. Performance levels of real-time AI will need to increase to meet the need.”
Choosing the right AI
There are a number of considerations in choosing the right AI design including project goals, accuracy requirements, flexibility, and central versus edge computing, and design tradeoffs.
1) Project goals
Choosing the right AI depends on the application requirements. Will you need generative AI or will predictive AI suffice? What are the complexity, accuracy, latency, safety, privacy, and security demands? Because AI is not free, it does not make sense to include AI just because everybody else is doing it. Sooner or later, the AI hype will vanish.
For example, in a general customer service application using a chatbot to guide the customer to the right department, natural language processing capability and fluency are important, but latency and safety are not a major concern. A couple of seconds delay does not matter that much. Conversely, in autonomous driving, accuracy, latency, safety and security are all very important. A few seconds of delay when braking may result in a crash. The in-cabin voice-controlled assistant to control the entertainment system is a different story. A malfunction may cause inconvenience, but not an emergency.
It is also important to keep in mind that each decision will impact the overall budget.
2) What is good enough?
Some developers tend to want perfection or, at a minimum, high-performance and accuracy at all costs. But for many AI applications, reaching 90% accuracy is good enough. Going beyond 95%, while doable, can be very costly. Therefore, start with the minimum requirement. If the task can be satisfied with 90% accuracy, stop there.
3) Accuracy
There are multiple considerations when making AI chip design decisions such as accuracy, performance, mobility, flexibility, and budget.
Ron Lowman, strategic marketing manager at Synopsys, believes that two simple questions determine what AI chip to use for what applications. “First, what minimum accuracy is required to be successful? Second, how much can you spend to get to that accuracy? AI is simply a new productivity tool that over time will be iterated by very smart engineers and entrepreneurs to improve a great number of processes, similar to electricity driving motors rather than hand cranks. If you need high accuracy with a reasonable budget, NVIDIA’s offering is the reasonable choice. However, if you can accept low accuracy and have a low budget, you can opt for much lower-cost AI chips or traditional SoCs with limited or even no AI acceleration. If these chips need to be mobile and highly efficient/low power, but on a low budget, a more efficient SoC with low accuracy can be acceptable. If you need high accuracy and low power, this is costly and needs an ASIC, or you must wait until we iterate for generations on new designs.”
The most expensive category is an SoC with lots of AI acceleration handling highly customized compressed algorithms. Automotive needs high accuracy and needs to be mobile and low power. “This means a new SoC must be designed that is more efficient than the highest-performance GPUs/AI SoCs, demanding massive investment. Then add the reliability components,” Lowman said.
The most important factor in AI design criteria is accuracy.
“Accuracy is usually impacted by bit resolution and/or algorithm choice,” Cooper said. “Using a transformer algorithm, which outperforms CNNs in accuracy, requires a neural network that supports the latest architectural advancements and enough bit resolution to achieve the accuracy — although very much algorithm-dependent. After accuracy, performance is of critical importance. All the accuracy in the world doesn’t help you if you can’t achieve a usable frame per second, even though it’s very much use-case dependent. Other factors are cost (often related to die area), power consumption, and ease of use of development tools.”
4) Flexibility
For designs that require flexibility and fast software upgrade, an embedded FPGA approach could be considered.
“When implementing AI, whether on chips or systems, it is important to be aware of the changing workload requirements of machine learning applications,” said Cheng Wang, CTO at Flex Logix. “You need design flexibility because the AI space is just evolving way too rapidly. You have a three-to-five-year design cycle for silicon, and you need to be software upgradeable immediately. We’re trying to drive awareness among developers.”
Centralized versus edge AI computing
While cloud computing provides AI solutions that require intense computing power, many other real-time applications such as smart city, retail, augmented reality, and preventive maintenance may benefit from edge AI.
However, that depends on the type of application being built and the resource bounds that must be worked within.
“Traditionally, from an AI perspective we’ve had a cloud-centric intelligence model,” said Renesas’ Vora. “If we truly want to enable intelligence at the extreme edge and endpoints in the network, it must be done in a way that’s highly efficient, responsive in real-time, and cost-effective.”
What this translates to is running cloud-independent inference engines on tiny computers within endpoints.
“A decentralized intelligence model has tremendous technical and economic benefits,” Vora said. “As a designer/architect/product developer, it is critical to consider AI/ML early in the definition phase and understand what resources and system constraints you must work with. There is a broad range of software and hardware architectures to choose from. When working with edge and endpoint applications, look for a partner/vendor that doesn’t just provide a chip but also a holistic ecosystem of AI/ML tools, reference solutions, and software to go along.”
AI/ML should be considered in the definition phase of the product, as hardware choices primarily will be driven by system-level requirements and resource constraints.
Most sensor-based applications can be addressed with simpler classical machine learning algorithms rooted in signal processing, mathematics, and statistics. More complex applications like machine vision and voice recognition require deep learning approaches. The complexity of the use case will influence hardware choices, including pure CPU with AI running in software, a CPU coupled with a neural acceleration engine, dedicated AI SoCs, and high-performance CPU/GPUs.
Looking ahead
There are two paths for AI. One delivers very high performance but will consume a great deal of energy. The other focuses more on energy efficiency with optimization. There are market demands for both.
New AI innovations for both software and hardware are expected to continue to evolve. Many new solutions are coming to the market from tech giants, as well as start-ups, including Axelera, SiMa.ai, Flex Logix, Quadric, Expedera, NeuReality, Kneron, Hailo.ai, and others. Here are a few examples coming from startups.
The “drag-and-drop,” no-code visual programming designed for ML edge computing is said to outperform some current leaders in the field based on the closed edge power category in the MLCommons ML Perf 3.1 benchmark.
Another advancement is in AI inference server architecture attempts to replace the traditional multi-purpose CPU-centric AI solutions. Running ChatGPT may cost millions of dollars a day. Operational efficiency is now becoming increasingly important. A system-level solution can optimize and scale the AI workflows to reduce the overall operational costs with the network attached processing unit. The new AI-centric approach is more hardware-based and can perform instruction processing faster.
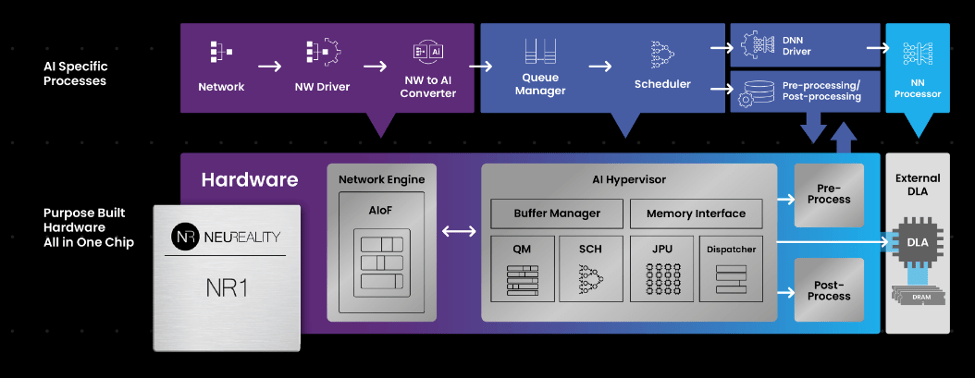
Fig. 1: A hardware-based AI-centric architecture relies on the network attached processing unit to perform much of the AI workflow. Source: NeuReality
Finally, while GPUs are getting a lot of attention in AI applications, an embedded FPGA is lower-power, more scalable, and more flexible when it comes to software updates. This is important because AI algorithms change very fast, both for improvements in performance and compatibility, and increasingly for security reasons.
Conclusion
AI innovations will continue to accelerate. In the long run, AI developments will be more capable, energy-efficient, and lower cost overall, giving developers more AI choices
Related Reading
Processor Tradeoffs For AI Workloads
Gaps are widening between technology advances and demands, and closing them is becoming more difficult.
How Chip Engineers Plan To Use AI
Checks, balances, and unknowns for AI/ML in semiconductor design.
Source: https://semiengineering.com/how-much-ai-is-really-needed/
