AI/ML training traditionally has been performed using floating point data formats, primarily because that is what was available. But this usually isn’t a viable option for inference on the edge, where more compact data formats are needed to reduce area and power.
Compact data formats use less space, which is important in edge devices, but the bigger concern is the power needed to move around that data. However, those data types may also result in lower accuracy. It becomes critical that the right data format is selected, but this is not always a straightforward task.
There are three primary types of data formats — fixed point, floating point, and logarithmic. Within each type, multiple options are possible. Floating point numbers contain an exponent that is useful for expressing dynamic range, and another exponent that is used to express significance. Eliminating the exponent results in a fixed-point number.
The presence of the exponent significantly increases the complexity of multiplication and addition, both of which are important operations for AI. Some example formats are shown in figure 1.

Fig. 1: Example data formats used for AI/ML. Source: Semiconductor Engineering
A Posit is a new type of logarithmic data format that creates a greater density of numbers between -1 and +1. It will be explained in more detail below.
All of this started with fp32. “The history of doing everything in floating point within GPUs was great to get things started,” says Stuart Clubb, principal product manager within Siemens Digital Industries Software. “But we are seeing that quantization and retraining based on what you’re actually trying to achieve, the level of accuracy you need, is indeed real and viable. And the impact at the edge is significant.”
Quantization reduces data sizes. “When you’re training the neural network, you’re training at very high precision and you need a much larger dynamic range to be able to support training convergence,” says Sharad Chole, chief scientist and co-founder of Expedera. “But during inference you really don’t need that much dynamic range. Just quantizing the values to 8 bits or 16 bits is good enough for most cases.”
The right data format depends upon the application. “Most people only need fixed-point version of those floating-point models for inferencing,” says Suhas Mitra, product marketing director for Tensilica AI products at Cadence. “Today, people are experimenting with even smaller versions of floating-point models, like bfloat16. For some workloads, 8-bit quantization may be sufficient. There is no reason for us to believe there will be one right answer. There’s no one quantization format for everything. That becomes very hard for a silicon company because they want to future-proof something.”
And that is only the start of the benefits. “If you reduce the size of the data, you immediately reduce the area needed to store that data,” says Russell Klein, program director for the Catapult HLS team at Siemens EDA. “If we look at the weights in an inference, those can be millions or even billions of values that need to be moved to the computational elements. If we can shrink it from 32 bits down to 16, or even 8, we get a 2X or a 4X improvement in our ability to move that data. Generally, the data movement and data storage tend to be our biggest bottlenecks, and our biggest power consumers.”
Quantization and compression
Quantization is a technique that reduces the amount of memory needed to store values. For example, if only 256 values are used for a particular weight, then it can be collapsed from a floating point to format to an 8-bit integer with no loss of information.
There are two methods for quantization. “When we talk about quantizing the weights and the features, we can do post-training quantization,” says Klein. “This means we take the weights calculated in training and compress them into a smaller format and call it good. With this method, you do need to check the accuracy. For example, if we decide to quantize to 7-bit values, you would need a 7-bit multiplier in your hardware. The only way to verify this without building the actual hardware is using Verilog or the AC data types — the bit accurate data types that are used in algorithmic C to do high-level synthesis. You also have to consider rounding, saturation, and other side effects that go into that calculation. Alternatively, you can do training-aware quantization. That’s where we would quantize the weights, and then go through a retraining session to re-quantize the weights. When you do that, you often arrive at a much smaller word size.”
Most networks contain several layers, where each may have different quantization. “Tools are evolving to the extent where we can understand the loss of quantization during the training phase,” says Expedera’s Chole. “When we can understand the loss of quantization, it becomes an easier process to iterate over. We can isolate a layer, and we can measure the precision of that layer. We can also put that layer back into the network and inspect the impact of 8-bit quantization versus 10-bit quantization. We can do this layer-by-layer. We can do a combination of layers and see how errors are being propagated.”
But even this can be tricky. “Assume you do find that 7-bit quantization is sufficient,” says Klein. “Those weights are probably not going to be accessed by any other algorithm or any other part of the system. If we are building our own accelerator, we can put in a 7-bit memory and hang that off the accelerator. That does not transfer over the general-purpose bus. You’re not going to try and make the CPU talk on that bus. If you need to store your weights in system memory, and you find that 7 bits is optimal, you might want to reorganize the network. You might want to take out some layers or take out some channels, and that’s going to make it a little bit less accurate. Then you’d want to add some bits to the representation, and that gets you up to 8 bits. By trading off the neural network architecture against your size, you can get nice powers of 2.”
The biggest advantage of quantization is that all of the computation costs happen at compile time. “There is even lookup table-based compression, where you compute a weight matrix based on decomposition and then update your weight matrix,” says Chole. “Some techniques are very specific to large language models. Other techniques are very specific to transformers. But in general, the cost of decompression for any of these techniques is not too high in hardware.”
While some have looked at dynamic compression, it brings in a host of additional challenges. “If you compress data, your accesses become a lot less regular,” says Klein. “Figuring out where the weights for this particular layer begin and end requires a lot of computation, or you need to keep a lot of pointers and do a lot of irregular accesses. The nice thing about having the raw data uncompressed is that it’s extremely regular. Computer systems have been designed very well to pull data from sequentially increasing memory locations at fixed sizes. But there’s a tradeoff. If you’ve got an extremely sparse network, it may pay off. Encoding 74 zeros, and then a value and then 22 zeros and then another value and so forth.”
When the compression is lossy, it can create problems. “For dynamic compression, you cannot do lossy,” says Chole. “We have seen lossy compression used in different pipelines, such as an image pipeline, but not in neural networks. Static compression can be lossy because you can evaluate the impact of lossy compression on accuracy. Quantization is a technique for lossy compression.”
Accuracy
A decision about data format is basically a decision about accuracy. “Is 8-bit data for activations good enough, or do I need to use 10-bit data for accuracy?” asks Chole. “Once that decision is made, then we have to find out what kind of architecture would be best suited for this. What sort of processing elements should I be supporting in the NPU to be able to execute the workload, in the best power and area footprint. Do you need FP16 for everything, which would mean your MAC is going to be fp16 natively? You also need to define what you’re going to accumulate into. Will you accumulate into fp16 or bfloat16 of fp32? There are many decision points. And the decision point typically is driven by the customer in terms of accuracy.”
The entire process becomes a set of tradeoffs. “The compute demand of neural networks is insatiable,” says Ian Bratt, fellow and senior director of technology at Arm. “The larger the network, the better the results and the more problems you can solve. But energy usage is proportional to the size of the network. Therefore, energy-efficient inference is absolutely essential in order to enable the adoption of more and more sophisticated neural networks and enhanced use cases, such as real-time voice and vision applications. This means looking at everything from new instructions to data types, such as OFP8 and MX formats. The efficiency of neural network edge inference has been improving exponentially, and we see no signs of it slowing down.”
Power savings can be exponential. “As we go from a floating-point representation to a fixed-point representation, the multipliers get to be about half as big,” says Klein. “If we shrink the values down from a 32-bit fixed point, down to say an 8-bit fixed point, that’s one quarter the data that we’re moving, but the multiplier gets to be 1/16 the size. It’s relative to the square of the size of the inputs. And as a result of that, what happens is we’ve got a much smaller area, much less power.”
A reduction in data format size has other benefits. One of the major problems for all computational units is that while performance has increased steadily, memory bandwidth has risen more slowly, and latency actually has increased. What this means is that if we are streaming data, every memory transfer takes as much time as 100 floating point arithmetic operations. In the case of memory latency, where you cannot pre-fetch and you miss the cache, you have lost the chance to do more than 4,000 floating point operations.
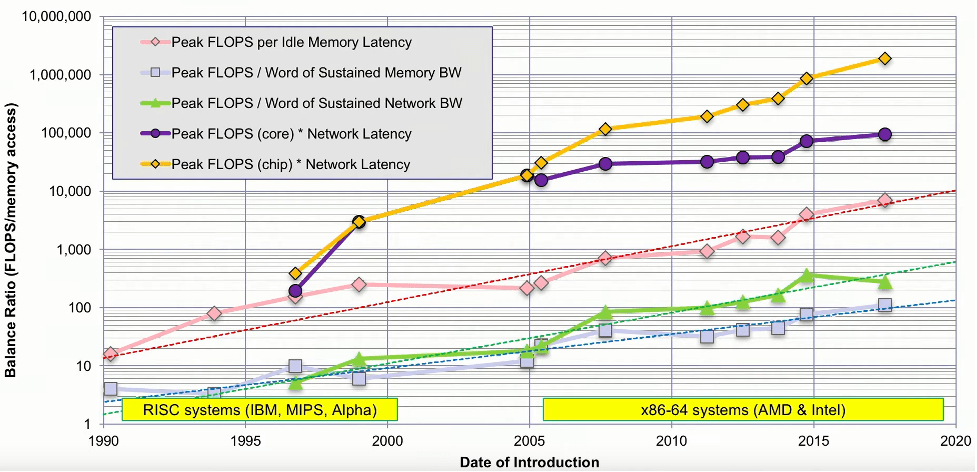
Fig. 2: Imbalance in elements of system performance. Source: John McCalpin, TACC, U. of Austin
The industry has a fascination with processing performance. “The capabilities of the compute unit, whatever it is, are important, but they’re often not the limiting factor in actual system speeds,” says Rob Aitken, a Synopsys fellow. “System speed is workload-dependent, and it’s determined by how fast data comes from someplace, gets processed somehow, and gets sent to wherever it is that it’s being used, subject to all of the miscellaneous constraints of everything along the way.”
Hardware flexibility
Hardware implementations often face conflicts between optimization and generalization. “You’re going to get the biggest gain from quantizing things when you go into a customized or bespoke accelerator,” says Klein. “An accelerator does one specific inference, or a small set of inferences that are closely related. Then you can build it specifically for that algorithm with your custom 13-bit fixed point numbers. Trying to do it in a general-purpose hardware is really challenging, and I don’t think anybody’s going to figure out a really good way to do that.”
How general does a general processor need to be? “You take a floating point 32-bit representation, the 8-bit exponent and the 2- bit mantissa plus sign bit, and you’re going to use a 24-bit multiplier,” says Siemens’ Clubb. “Maybe you can fragment that up into three 8-bit multipliers, but how can you actually make the best use of all of that hardware, and what penalty are you paying for that? Then you start getting into brain float. Am I going to do half float? The number of permutations in the hardware that you need to build is just going to explode. Even when you look at GPUs today — fantastic, super-fast floating point, insane power, not going to put it at the edge, and then you go TPU, or general-purpose, where maybe I’ll do 32 bit, maybe I’ll do half float, maybe I might give you brain float — every single time you do that from a hardware design perspective you’re building in stuff that may or may not get used.”
You may need to keep your options somewhat open. “In the RISC-V world, the new vector engine has been ratified,” says Simon Davidmann, CEO for Imperas. “You can configure the engine to be 32-bit floating point, bfloat16 or fixed-point. They built the vector engines so if you’ve got a 32-bit word, but are processing 8-bit, you can do the computations in parallel. It is a single-instruction, multiple-data (SIMD) engine. You get better throughput because you use less cycles to do more operations. This means the architecture is a little more complex, but it means you get more computation per cycle without increasing the silicon much.”
The options are limited, though. “Doing general-purpose hardware, and trying to support multiple formats, is really challenging — and it brings in a lot of overhead,” says Klein. “What we see is people who are generating general-purpose hardware will support float32 and they’ll probably take some integer or fixed-point format. We’ve seen a lot of designs support 32-bit float and an 8-bit Int. Trying to support different types of formats incurs so much overhead that you lose a lot of the benefits. You are trying to save area, save power, but then you throw in all this extra logic to manage these different types and you start using up area and using up power.”
The approach taken by Quadric includes a full 32-bit integer ALU paired with each bank of octal 8 x 8 MAC units. “This allows most layers to run in energy-efficient int8 mode, yet preserves the ability to operate high-precision layers using 32-bit fixed-point representation,” says Nigel Drego, CTO and co-founder of Quadric. “Coupled with an advanced neural net graph compiler, the dynamic range of values at each layer is analyzed and assigned numerical formats (fractional bits, scaling factors) most appropriate to each specific layer. Those format choices can vary through a network as needs dictate. We knew we needed more precision than just pure int8 for every layer, but traditional floating point is far too expensive in area and power. Using 32-bit fixed point, in parallel with int8, gives us the best of both approaches.”
It all comes down to what is optimal for a particular task. “There is a cost to it obviously, because you need to decide what your native support is for the MAC,” says Chole. “What your MACs are natively built for — int4 x int4, or int8 x int8, or int16 x int16 — and that has a cost in terms of power. If you’re using larger macros to support smaller operations, then obviously your power is going to be more. There is going to be some sort of latency criteria that’s going to be slightly higher than what your int8 was, and area is going to be higher. This is really a workload optimization problem.”
For many networks different precisions are required for each layer, and if you want hardware reuse, then supporting multiple formats becomes essential. “What we see happening is we are not just limited to 8-bit or 16-bit,” says Chole. “Customers are asking us for 4-bit, 6-bit, 8-bit, 10-bit, and it changes across the network. Some networks might be 10-bit, another network might be 16-bit, and some networks will be completely mixed-mode. For example, the first few layers and last few layers are 16-bit, versus the middle portion of the network, which is 8 bit. These are the considerations we need to do in order to get the best possible area footprint and power footprint. If you try to optimize area too much, you’re paying in power, you’re paying in muxes. You do not want to do that for your 90% of the workload, just for the 10% of the higher-precision workload. It’s a fine line to walk, but it is an experiment-driven fine line.”
Posits
There are many applications where you need a lot of data precision between -1, zero and +1, but outside of that range things can be less precise. Neither fixed nor floating point formats are good for this. A new type of data format is being introduced, called log formats or Posits, that can be either.
A posit is more difficult to understand than the other formats because it is dynamic. Both the regime bits (see figure 1), and the exponent bits are variable size. Regime bits are either all 0s or all 1s. If the first bit after the sign bit is a 0, then the regime bits continue until you run out of bits or encounter a 1. Similarly, if the first bit after the sign bit is a 1, the regime bits continue until you run out of bits or encounter a 0. If there are any bits left, the exponent bits are next in line. There may be no exponent bits. There also may be no fraction bits.
“Some people are starting to look at logarithmic values,” says Klein. “It makes the multipliers a lot easier. Multipliers using logarithm values are just adding things, but it makes the adders much more complicated. Another thing you can do to customize how tightly and how precise the numbers are at different areas is to use lookup tables. If we can reduce it down to 32 or 64 values that we need in our computation, rather than storing those numbers as numbers that we use in the calculations, we can then go through an indirection through a lookup table. And then we can have lots of numbers clustered around zero and one, and then spread things out as we get toward the larger numbers.”
Conclusion
Picking the right data format, or formats, for a given AI task is not easy. This is not just a software task or a hardware task. Instead, it’s a complex co-design task that is trading off network design with accuracy, area, computational power, transfer bandwidth, and power. Tools are still emerging that will help developers understand these tradeoffs.
New data formats also are being developed that are tuned to AI, rather than using data formats that were developed for more traditional processing. While float32 was convenient in the early days, it is often not the best choice today.
Further Reading
AI Races To The Edge
Inferencing and some training are being pushed to smaller devices as AI spreads to new applications.
Will Floating Point 8 Solve AI/ML Overhead?
Less precision equals lower power, but standards are required to make this work.
The post Data Formats For Inference On The Edge appeared first on Semiconductor Engineering.
Source: https://semiengineering.com/data-formats-for-inference-on-the-edge/
