Healthcare data is complex and siloed, and exists in various formats. An estimated 80% of data within organizations is considered to be unstructured or “dark” data that is locked inside text, emails, PDFs, and scanned documents. This data is difficult to interpret or analyze programmatically and limits how organizations can derive insights from it and serve their customers more effectively. The rapid rate of data generation means that organizations that aren’t investing in document automation risk getting stuck with legacy processes that are manual, slow, error prone, and difficult to scale.
In this post, we propose a solution that automates ingestion and transformation of previously untapped PDFs and handwritten clinical notes and data. We explain how to extract information from customer clinical data charts using Amazon Textract, then use the raw extracted text to identify discrete data elements using Amazon Comprehend Medical. We store the final output in Fast Healthcare Interoperability Resources (FHIR) compatible format in Amazon HealthLake, making it available for downstream analytics.
Solution overview
AWS provides a variety of services and solutions for healthcare providers to unlock the value of their data. For our solution, we process a small sample of documents through Amazon Textract and load that extracted data as appropriate FHIR resources in Amazon HealthLake. We create a custom process for FHIR conversion and test it end to end.
The data is first loaded into DocumentReference. Amazon HealthLake then creates system-generated resources after processing this unstructured text in DocumentReference and loads it into Condition, MedicationStatement, and Observation resources. We identify a few data fields within FHIR resources like patient ID, date of service, provider type, and name of medical facility.
A MedicationStatement is a record of a medication that is being consumed by a patient. It may indicate that the patient is taking the medication now, has taken the medication in the past, or will be taking the medication in the future. A common scenario where this information is captured is during the history-taking process in the course of a patient visit or stay. The source of medication information could be the patient’s memory, a prescription bottle, or from a list of medications the patient, clinician, or other party maintains.
Observations are a central element in healthcare, used to support diagnosis, monitor progress, determine baselines and patterns, and even capture demographic characteristics. Most observations are simple name/value pair assertions with some metadata, but some observations group other observations together logically, or could even be multi-component observations.
The Condition resource is used to record detailed information about a condition, problem, diagnosis, or other event, situation, issue, or clinical concept that has risen to a level of concern. The condition could be a point-in-time diagnosis in the context of an encounter, an item on the practitioner’s problem list, or a concern that doesn’t exist on the practitioner’s problem list.
The following diagram shows the workflow to migrate unstructured data into FHIR for AI and machine learning (ML) analysis in Amazon HealthLake.
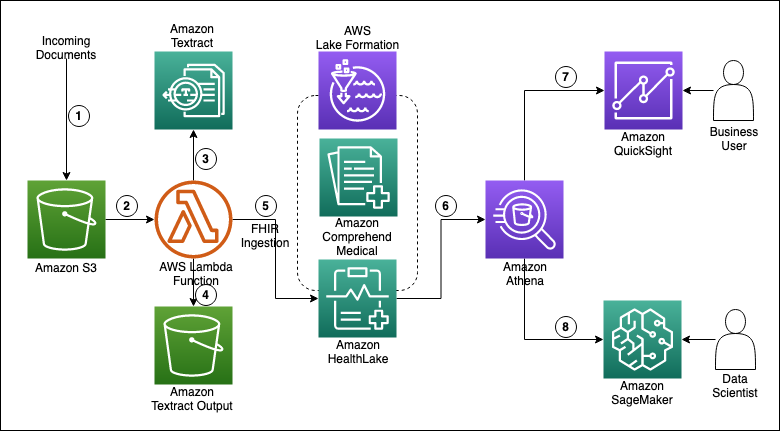
The workflow steps are as follows:
- A document is uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
- The document upload in Amazon S3 triggers an AWS Lambda function.
- The Lambda function sends the image to Amazon Textract.
- Amazon Textract extracts text from the image and stores the output in a separate Amazon Textract output S3 bucket.
- The final result is stored as specific FHIR resources (the extracted text is loaded in
DocumentReferenceas base64 encoded text) in Amazon HealthLake to extract meaning from the unstructured data with integrated Amazon Comprehend Medical for easy search and querying. - Users can create meaningful analyses and run interactive analytics using Amazon Athena.
- Users can build visualizations, perform ad hoc analysis, and quickly get business insights using Amazon QuickSight.
- Users can make predictions with health data using Amazon SageMaker ML models.
Prerequisites
This post assumes familiarity with the following services:
By default, the integrated Amazon Comprehend Medical natural language processing (NLP) capability within Amazon HealthLake is disabled in your AWS account. To enable it, submit a support case with your account ID, AWS Region, and Amazon HealthLake data store ARN. For more information, refer to How do I turn on HealthLake’s integrated natural language processing feature.
Refer to the GitHub repo for more deployment details.
Deploy the solution architecture
To set up the solution, complete the following steps:
- Clone the GitHub repo, run
cdk deploy PdfMapperToFhirWorkflowfrom your command prompt or terminal and follow the README file. Deployment will complete in approximately 30 minutes. - On the Amazon S3 console, navigate to the bucket starting with
pdfmappertofhirworkflow-, which was created as part ofcdk deploy.
- Inside the bucket, create a folder called uploads and upload the sample PDF (SampleMedicalRecord.pdf).

As soon as the document upload is successful, it will trigger the pipeline, and you can start seeing data in Amazon HealthLake, which you can query using several AWS tools.
Query the data
To explore your data, complete the following steps:
- On the CloudWatch console, search for the
HealthlakeTextractlog group.
- In the log group details, note down the unique ID of the document you processed.

- On the Amazon HealthLake console, choose Data Stores in the navigation pane.
- Select your data store and choose Run query.
- For Query type, choose Search with GET.
- For Resource type, choose DocumentReference.
- For Search parameters, enter the parameter as relates to and the value as
DocumentReference/Unique ID. - Choose Run query.

- In the Response body section, minimize the resource sections to just view the six resources that were created for the six-page PDF document.

- The following screenshot shows the integrated analysis with Amazon Comprehend Medical and NLP enabled. The screenshot on the left is the source PDF; the screenshot on the right is the NLP result from Amazon HealthLake.

- You can also run a query with Query type set as Read and Resource type set as Condition using the appropriate resource ID.

The following screenshot shows the query results.
- On the Athena console, run the following query:

Similarly, you can query MedicationStatement, Condition, and Observation resources.
Clean up
After you’re done using this solution, run cdk destroy PdfMapperToFhirWorkflow to ensure you don’t incur additional charges. For more information, refer to AWS CDK Toolkit (cdk command).
Conclusion
AWS AI services and Amazon HealthLake can help store, transform, query, and analyze insights from unstructured healthcare data. Although this post only covered a PDF clinical chart, you could extend the solution to other types of healthcare PDFs, images, and handwritten notes. After the data is extracted into text form, parsed into discrete data elements using Amazon Comprehend Medical, and stored in Amazon HealthLake, it could be further enriched by downstream systems to drive meaningful and actionable healthcare information and ultimately improve patient health outcomes.
The proposed solution doesn’t require the deployment and maintenance of server infrastructure. All services are either managed by AWS or serverless. With AWS’s pay-as-you-go billing model and its depth and breadth of services, the cost and effort of initial setup and experimentation is significantly lower than traditional on-premises alternatives.
Additional resources
For more information about Amazon HealthLake, refer to the following:
About the Authors
 Shravan Vurputoor is a Senior Solutions Architect at AWS. As a trusted customer advocate, he helps organizations understand best practices around advanced cloud-based architectures, and provides advice on strategies to help drive successful business outcomes across a broad set of enterprise customers through his passion for educating, training, designing, and building cloud solutions. In his spare time, he enjoys reading, spending time with his family, and cooking.
Shravan Vurputoor is a Senior Solutions Architect at AWS. As a trusted customer advocate, he helps organizations understand best practices around advanced cloud-based architectures, and provides advice on strategies to help drive successful business outcomes across a broad set of enterprise customers through his passion for educating, training, designing, and building cloud solutions. In his spare time, he enjoys reading, spending time with his family, and cooking.
 Rafael M. Koike is a Principal Solutions Architect at AWS supporting Enterprise customers in the South East, and is part of the Storage and Security Technical Field Community. Rafael has a passion to build, and his expertise in security, storage, networking, and application development has been instrumental in helping customers move to the cloud securely and fast.
Rafael M. Koike is a Principal Solutions Architect at AWS supporting Enterprise customers in the South East, and is part of the Storage and Security Technical Field Community. Rafael has a passion to build, and his expertise in security, storage, networking, and application development has been instrumental in helping customers move to the cloud securely and fast.
 Randheer Gehlot is a Principal Customer Solutions Manager at AWS. Randheer is passionate about AI/ML and its application within HCLS industry. As an AWS builder, he works with large enterprises to design and rapidly implement strategic migrations to the cloud and build modern, cloud-native solutions.
Randheer Gehlot is a Principal Customer Solutions Manager at AWS. Randheer is passionate about AI/ML and its application within HCLS industry. As an AWS builder, he works with large enterprises to design and rapidly implement strategic migrations to the cloud and build modern, cloud-native solutions.
