Web pages are filled with relevant data, but extracting data from multiple web pages daily for multiple purposes like competitive analysis, research, or more can be hectic.
Web scraping tools simplify extracting data from websites.
Compared to manually scraping webpages, web scraping tools help to save a lot of time and effort, which can be used to accomplish other important tasks of the organization. Of course, while extracting the data from websites, there is a risk of IP getting banned or extracting the data in a compatible format. Therefore, selecting a great web scraping tool becomes important.
This blog will show the top 10 web scraping tools for scraping data from web pages easily and efficiently.
Extract text from any webpage in just one click. Head over to Nanonets website scraper, Add the URL and click “Scrape,” and download the webpage text as a file instantly. Try it for free now.
What Is Web Scraping?
Web scraping is a method to collect or extract data from any website. Webscraper extracts HTML structure, tables, images, and text from the website and stores it in the format of choice.
Web Scraping can be used for multiple use cases like competitive intelligence, creating a database, maintaining real-time updates, and more. Web scraping tools help businesses and individuals automate the entire web scraping process while using advanced features like IP proxy rotation, automated data enhancement, and integrations.
Scrape any webpage in seconds using the Nanonets website scraping tool. It’s free. Try now.
Given below are the best web scraper tools:
#1. Smartproxy
Smartproxy is one of the best web scraper tools that extract data and content from websites instantly and effortlessly. It provides the data in the form of raw HTML from websites. It accomplishes this task by sending an API request. Not only this, but this tool also keeps on sending requests so that the data or content required by the company should be extracted with utmost accuracy.
Key Features of Smartproxy:
- Provides real-time data collection
- Provides real-time proxy-like integration
- Data extracted in raw HTML
Pros of Smartproxy:
- Global proxies power this tool.
- Provides live customer support to the users
- No CAPTCHAs as it comes with advanced proxy rotation
Cons of Smartproxy:
- Sometimes email support is slow
- It does not allow for web elements to be rendered
- Expensive plan
- Should incorporate more auto extractors
- Requests could get a timeout
#2. Nanonets Web Scraping Tool
Nanonets has a powerful OCR API that can scrape webpages with 100% accuracy. It can detect images, tables, text and characters with highest accuracy. What differentiates Nanonets from other tools is the ability to automate web scraping using automated workflows.
Users can set up workflows to automatically scrape webpages, format the extracted data and then export the scraped data to 500+ integrations at a click of a button.
Key Features of Nanonets:
- Provides real-time data extraction from any kind of webpage
- Extracts HTML tables with high accuracy
- Format data automatically
Pros of Nanonets:
- 24×7 live support
- Can extract data from all types of webpages – Java, Headless or Static Pages
- No-code user interface
- Workflow automation is possible
Cons of Nanonets:
- Can’t scrape images and videos
#3. Scraper API
Scraper API allows easy integration; you just need to get a request and a URL. Moreover, users can get more advanced use cases in the documentation. It also provides geo-located rotating proxies, which help route the request through the proxies.
Features of Scraper API:
- Allows easy integration
- Allows users to scrape JavaScript-rendered pages as well
Pros of Scraper API:
- Easy to use
- Completely customizable
- It is fast and reliable
Cons of Scraper API:
- There are some websites where this tool does not function
- It is a bit costly
- Some features, such as javascript scraping, are very expensive
- Should enhance the ability to scale the plan’s calls
- While calling the API, the headers of the response are not there
#4. Web Scraper
Web Scraper is a web scraping provides a cloud-based platform for accessing the extracted data. It has an easy-to-use interface, so it can also be used by beginners. Also, it allows extracting data or content even from dynamic websites.
Features of Web Scraper:
- It enables data extraction from websites with categories and sub-categories
- Modifies data extraction as the site structure changes
Pros of Web Scraper:
- It is a cloud-based web scraper
- Extracted data is accessible through the API
Cons of Web Scraper:
- Should provide extra credits in the trial plan
- High pricing for small users
- Several internal server errors
- Website response is very slow sometimes
- It should include more video documentation.
#5. Grepsr

Grepsr allows users to capture the data, modify it, and put it into the PC. It can be used by users personally, marketers, and investors professionally.
Pros of Grepsr:
- It supports multiple output formats.
- Provided the service of unlimited bandwidth
Cons of Grepsr:
- Sometimes it can be inconvenient to extract data
- Being in a different timezone can lead to latency
- There are errors while extracting the data
- Sometimes the request gets timed out
- Sometimes data needs to be re-processed due to inconsistency.
#5. ParseHub
ParseHub is a famous web scraping tool that has an easy-to-use interface. It provides an easy way to extract data from websites. Moreover, it can extract the data from multiple pages and interact with AJAX, dropdown, etc.
Features of ParseHub:
- Allows data aggregation from multiple websites
- REST API for building mobile and web apps
Pros of ParseHub:
- It has an easy-to-use interface
- Beginners can use it as well
Cons of ParseHub:
- It is a desktop app
- Users face problems with bugs
- Costly web scraping tool
- The limit of pages to extract on the free version is very low
#7. Scrapy
Scrapy is another web scraping tool that acts as an open-source platform and allows users to extract data from different websites. This web scraping tool is written in Python and works as a collaborative framework. Moreover, the tool supports Mac, Windows, Linux, and BSD.
Features of Scrapy:
- This tool is easily extensible and portable.
- Helps to create own web spiders.
- These web spiders can be deployed to Scrapy cloud or servers.
Pros of Scrapy:
- This tool is very reliable
- It provides rapid scalability
- Provides excellent support service to the users
Cons of Scrapy:
- Expensive
- Challenging to use by a non-professional
- Hard to create a simple and clear user interface for beginners
- Lack of monitoring and alerting,
- It has a non-convenient logging system
#8. Mozenda
Mozenda is another web scraping tool that provides data harvesting and wrangling services. These services are accessible to users on the cloud and on-premises. Moreover, it also allows users to prepare data for many operations, such as marketing and finance.
Features of Mozenda:
- This tool helps to accomplish simultaneous processing
- Data collection can be controlled through API
- It allows data scraping for websites from several geographical locations.
- Provided the facility of email notifications.
Pros of Mozenda:
- It provided both cloud-based and on-premises solutions for data extraction
- Allows users to download files and images
- Provided excellent API features
Cons of Mozenda:
- It has complicated scraping requirements that are hard to achieve
- It can be hard to find relevant documentation
- Hard to understand and use programming terms
- Does not provide enough testing functionality.
- Users may face RAM issues when dealing with huge websites.
#9. Dexi
Dexi is a popular web scraping tool providing users with accurate data extraction. Except for data extraction, this web scraping tool also helps with monitoring, interaction, and data processing. Moreover, it provides data insights into the content, allowing the organization to make better company decisions and enhancing its functioning.
Features of Dexi:
- It allows data extraction from any site
- This tool has features for aggregating, transforming, manipulating, and combining data.
- It has tools for debugging.
Pros of Dexi:
- This tool is easily scalable
- It supports many third-party services.
Cons of Dexi:
- This tool is very complicated to understand
- It lacks some advanced functionality
- Documentation could be enhanced
- API endpoints are not available
- Nonintuitive UI UX
#10. Common Crawl
Common Crawl is a web scraping tool developed for anyone wanting to analyze data and look for meaningful insights. It also allows anyone to use this web scraping tool for free as it is a registered non-profit platform that works on donations to keep its functions running smoothly.
Key Features of Common Crawl:
- Support for non-code-based use cases
- It gives resources for educators to teach and analyze data
- Open datasets of raw web page data
Pros of Common Crawl:
- Good for beginners
- It has a user-friendly dashboard
- Documentations are available easily
- Provides data accuracy
Cons of Common Crawl:
- Support for live data is not available
- Support for AJAX-based sites is also not available
- The data available in this tool is not structured
- Data can not be filtered.
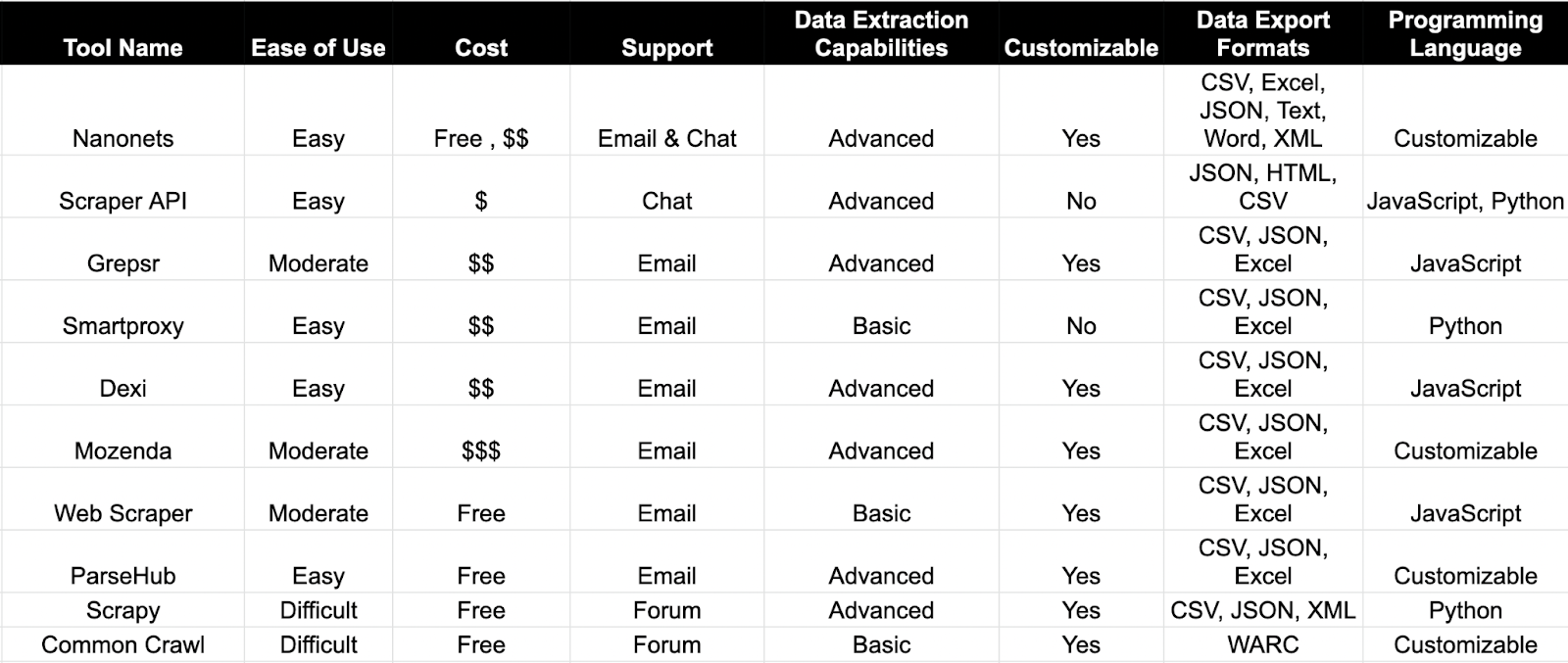
Here is a comparison table to compare the web scraping tools mentioned above:
Conclusion
I’ve listed major web scraping tools here to automate web scraping easily. Web Scraping is a legally grey area, and you should consider its legal implications before using a web scraping tool.
Web scraping tools mentioned above can simplify scraping data from webpages easily. If you need to automate web scraping for larger projects, you can contact Nanonets.
We also have a free website scraping tool to scrape webpages instantly.
FAQs
How do Web Scrapers Work?
The function of web scrapers is to extract data from websites quickly and accurately. The process of data extraction is as follows:
Making an HTTP request to a server
The first step in the web scraping process is making an HTTP request when a person visits a website. This means asking to access a particular site that contains the data. To access any site, web scraper needs permission, which is why the initial thing to do is send an HTTP request to the site from which there is a need for the content.
Extracting and parsing the website’s code
After getting permission to access the website, the work of web scrapers is to read and extract the HTML code of that website. After this, the web scraping tools break the content down into small parts, also known as parsing. It helps to identify and extract elements such as text IDs, tags, etc.
Saving the relevant data locally
After accessing the HTML code, and extracting and parsing it, the next step is to save the data in a local file. The data is saved as a structured format in an Excel file.
Different Types of Web Scrapers
Web Scrapers can be divided based on several different criteria, such as:
Self-Built or Pre-Built Web Scrapers
To program a self-built web scraper, you need advanced knowledge of programming. So to build a more advanced web scraper tool, you need more advanced knowledge to function as per the company’s requirements.
While pre-built web scrapers are developed and can be downloaded and operated on the go, it also contains advanced features that can be customized per the needs.
Browser Extension or Software Web Scrapers
Browser extensions web scrapers are easy to function as they can be added to your web browser. However, because these web scrapers can be integrated with the web browser, they are limited because any feature not in the web browser can’t be operated on this web scraper.
On the other hand, software web scrapers are not limited to web browsers only. That means they can be downloaded on your PC. In addition, these web scrapers have more advanced features; that is, any feature outside your web browser can be accessed.
Cloud or Local Web Scrapers
Cloud Web Scrapers function on the cloud. It is basically an off-site server that the web scraper company itself provides. It helps the PC to not use its resources to extract data and thus accomplish other functions of the PC.
While local web scrapers function on your PC and use the local resources to extract data, in this case, the web scrapers require more RAM, thus making your PC slow.
What is Web Scraping used for?
Web Scraping can be used in numerous organizations. Some of the uses of web scraping tools are as follows:
Price Monitoring
Many organizations and firms use web scraping techniques to extract the data and price related to particular products and then compare it with other products to make pricing strategies. This helps the company fix the product price to increase its sales and maximize profits.
News Monitoring
Web scraping news sites help extract the data and content about the latest trends of the organization. The data and reports of the companies that are recently in trend are available, and this helps the organization plan its marketing methods.
Sentiment Analysis
To enhance the quality of the products, there is a need to understand the views and feedback of the customers. Due to this, sentiment analysis is done. Web scraping is used to make this analysis by collecting data from various social media sites about particular products. This helps the company to make changes in their products as per the wishes of the customers.
Market Research
Market research is another use of web scraping tools. It involves collecting extracted data in huge volumes to analyze customer trends. This helps them make such products to increase the customers’ popularity.
Email Marketing
Web scraping tools are used for email marketing as well. This process involves collecting the email ids of the people from websites. Then the companies send the promotional ads to these email IDs. This has been proven an excellent marking technique in recent years.
