From ordering groceries through Instamart and wardrobe shopping in Myntra to booking vacations on MakemyTrip, websites have become indispensable in this decade! Ever wondered how these websites display information to customers in an easily-interpretable way and also process and interact with the data in the backend?
There are certain file formats that bridge this gap, being interpretable to both machine language and humans. One such widely used format is XML, which stands short for Extensible Markup Language.
What are XML files, and how do we use them?
XML files are used to store and transport data between clients and servers. It allows us to define the data in a structured format through tags, attributes, and values. One of the main advantages of XML is its flexibility. It can be used to represent data in many formats and easily adapted to new uses. This makes it a popular choice for applications such as web services, data exchange, and configuration files.In this article, I’ll take you through the different methods in python to parse an XML file with a practical example.
Are you looking for automate XML Parsing? Try Nanonets automated workflows. Start your free trial now.
Understanding the structure of XML files
Before we dive into the details of how to parse XML files, let’s first understand the different parts of an XML document. In XML, an element is a fundamental building block of a document that represents a structured piece of information. The element’s content has to be enclosed between an opening tag and a closing tag always as shown below.
<title>Harry Potter and the Sorcerer’s Stone</title>
I’ll be using an example file, “travel_pckgs.xml,” which contains details of the different tour packages offered by a company. I’ll continue to use the same file throughout the blog for clarity.
<?xml version="1.0"?>
<travelPackages>
<package id='Paris vacation'>
<description>Experience the magnificent beauty of Paris and the french culture.</description>
<destination>Paris, France</destination>
<price>3000</price>
<duration>7</duration>
<payment>
<EMIoption>yes</EMIoption>
<refund>yes</refund>
</payment>
</package>
<package id='Hawaii Adventure'>
<description>Embark on an exciting adventure in Hawaii beaches!
</description>
<destination>Hawaii, USA</destination>
<price>4000</price>
<duration>10</duration>
<payment>
<EMIoption>no</EMIoption>
<refund>no</refund>
</payment>
</package>
<package id='Italian Getaway'>
<description>Indulge in the beauty and charm of Italy and get an all-
inclusive authentic Italian food tour!</description>
<destination>Italy</destination>
<price>2000</price>
<duration>8</duration>
<payment>
<EMIoption>yes</EMIoption>
<refund>no</refund>
</payment>
</package>
<package id='Andaman Island Retreat'>
<description>Experience the beauty of Island beaches,inclusive scuba
diving and Night kayaking through mangroves.</description>
<destination>Andaman and Nicobar Islands</destination>
<price>800</price>
<duration>8</duration>
<payment>
<EMIoption>no</EMIoption>
<refund>yes</refund>
</payment>
</package>
</travelPackages>The file has data of 4 tour packages, with details of destination, description, price and payment options provided by an agency. Let’s look at the breakdown of the different parts of the above XML:
- Root Element: The topmost level element is referred as the root, which is <travelPackages> in our file. It contains all the other elements( various tours offered)
- Attribute: ‘id’ is the attribute of each <package> element in our file. Note that the attribute has to have unique values (‘Paris vacation’, ‘Hawaii Adventure’, etc) for each element. The attribute and its value is usually mentioned inside the start tag as you can see.
- Child Elements: The elements wrapped inside the root are the child elements. In our case, all the <package> tags are child elements, each storing details about a tour package.
- Sub-Elements: A child element can have more sub-elements inside its structure. The <package> child element has sub-elements <description>, <destination>, <price>, <duration> and <payment>. The advantage of XML is that it allows you to store hierarchical information through multiple nested elements. The <payment> sub-element further has sub-elements <EMIoption> and <refund>, which denote whether a particular package has ‘pay through EMI’ and refund options or not.
Tip: You can create a Tree view of the XML file to gain a clear understanding using this tool. Check out the hierarchical tree view of our XML file!

Great! We want to read the data stored in these fields, search for, update, and make changes as needed for the website, right? This is called parsing, where the XML data is split into pieces and different parts are identified.
There are multiple ways to parse an XML file in python with different libraries. Let’s dive into the first method!
Try Nanonets to parse XML files. Start your free trial without any credit card details.
Using Mini DOM to parse XML files
I’m sure you would have encountered DOM (Document Object Model), a standard API for representing XML files. Mini DOM is an inbuilt python module that minimally implements DOM.
How does mini DOM work?
It loads the input XML file into memory, creating a tree-like structure “DOM Tree” to store elements, attributes, and text content. As XML files also inherently have a hierarchical-tree structure, this method is convenient to navigate and retrieve information.
Let’s see how to import the package with the below code. You can parse the XML file using xml.dom.minidom.parse() function and also get the root element.
import xml.dom.minidom
# parse the XML file
xml_doc = xml.dom.minidom.parse('travel_pckgs.xml')
# get the root element
root = xml_doc.documentElement
print('Root is',root)The output I got for the above code is:
>> Root is <DOM Element: travelPackages at 0x7f05824a0280>Let’s say I want to print each package’s place, duration, and price.
The getAttribute() function can be used to retrieve the value of an attribute of an element.
If you want to access all the elements under a particular tag, use the getElementsByTagName() method and provide the tag as input. The best part is that getElementsByTagName() can be used recursively, to extract nested elements.
# get all the package elements
packages = xml_doc.getElementsByTagName('package')
# loop through the packages and extract the data
for package in packages:
package_id = package.getAttribute('id')
description = package.getElementsByTagName('description')[0].childNodes[0].data
price = package.getElementsByTagName('price')[0].childNodes[0].data
duration = package.getElementsByTagName('duration')[0].childNodes[0].data
print('Package ID:', package_id)
print('Description:', description)
print('Price:', price)The output of the above code is shown here, with the ID, description text, and price values of each package extracted and printed.
Package ID: Paris vacation
Description: Experience the magnificent beauty of Paris and the french culture.
Price: 3000
Package ID: Hawaii Adventure
Description: Embark on an exciting adventure in Hawaii beaches!
Price: 4000
Package ID: Italian Getaway
Description: Indulge in the beauty and charm of Italy and get an all-inclusive authentic Italian food tour!
Price: 2000
Package ID: Andaman Island Retreat
Description: Experience the beauty of Island beaches,inclusive scuba
diving and Night kayaking through mangroves.
Price: 800Minidom parser also allows us to traverse the DOM tree from one element to its parent element, its first child element, last child, and so on. You can access the first child of the <package> element using the firstChild attribute. The extracted child element’s node name and value can also be printed through nodeName and nodeValue attributes as shown below.
# get the first package element
paris_package = xml_doc.getElementsByTagName('package')[0]
# get the first child of the package element
first_child = paris_package.firstChild
#print(first_child)
>>
<DOM Element: description at 0x7f2e4800d9d0>
Node Name: description
Node Value: NoneYou can verify that ‘description’ is the first child element of <package>. There’s also an attribute called childNodes that will return all the child elements present inside the current node. Check the below example and its output.
child_elements=paris_package.childNodes
print(child_elements)
>>
[<DOM Element: description at 0x7f057938e940>, <DOM Element: destination at 0x7f057938e9d0>, <DOM Element: price at 0x7f057938ea60>, <DOM Element: duration at 0x7f057938eaf0>, <DOM Element: payment at 0x7f057938eb80>]Similar to this, minidom provides more ways to traverse like parentNode, lastChild nextSibling, etc. You can check all the available functions of the library here.
But, a major drawback of this method is the expensive memory usage as the entire file is loaded into memory. It’s impractical to use minidom for large files.
Automate XML parsing Nanonets. Start your free trial today. No credit card is required.
Using ElementTree Library to parse XML files
ElementTree is a widely used built-in python parser that provides many functions to read, manipulate and modify XML files. This parser creates a tree-like structure to store the data in a hierarchical format.
Let’s start by importing the library and calling our XML file’s parse() function. You can also provide the input file in a string format and use the fromstring() function. After we initialize a parsed tree, we can use get root () function to retrieve the root tag as shown below.
import xml.etree.ElementTree as ET
tree = ET.parse('travel_pckgs.xml')
#calling the root element
root = tree.getroot()
print("Root is",root)
Output:
>>
Root is <Element 'travelPackages' at 0x7f93531eaa40>The root tag ‘travelPackages’ is extracted!
Let’s say now we want to access all the first child tags of the root. We can use a simple for loop and iterate over it, printing the child tags like destination, price, etc…Note that if we had specified an attribute value inside the opening tag of the description, the parentheses wouldn’t be empty. Check out the below snippet!
for x in root[0]:
print(x.tag, x.attrib)
Output:
>>
description {}
destination {}
price {}
duration {}
payment {}Alternatively, the iter() function can help you find any element of interest in the entire tree. Let’s use this to extract the descriptions of each tour package in our file. Remember to use the ‘text’ attribute to extract the text of an element.
For x in root.iter('description'):
print(x.text)
Output:
>> "Experience the magnificent beauty of Paris and the french culture." "Embark on an exciting adventure in Hawaii beaches!" "Indulge in the beauty and charm of Italy and get an all-inclusive authentic Italian food tour!" "Experience the beauty of Island beaches,inclusive scuba diving and Night kayaking through mangroves.While using ElementTree, the basic for loop is pretty powerful to access the child elements. Let’s see how.
Parsing XML files with a for loop
You can simply iterate through the child elements with a for loop, extracting the attributes as shown below.
for tour in root:
print(tour.attrib)
Output:
>>
{'id': 'Paris vacation'}
{'id': 'Hawaii Adventure'}
{'id': 'Italian Getaway'}
{'id': 'Andaman Island Retreat'}To handle complex querying and filtering, ElementTee has the findall() method. This method lets you access all the child elements of the tag passed as parameters. Let’s say you want to know the tour packages that are under $4000, and also have EMIoption as ‘yes’. Check the snippet.
for package in root.findall('package'):
price = int(package.find('price').text)
refund = package.find('payment/refund').text.strip("'")
if price < 4000 and refund == 'yes':
print(package.attrib['id'])We basically iterate over packages through root.findall(‘package’) and then extracts the price and refund with find() method. After this, we check the constraints and filter out the qualified packages that are printed below.
Output:
>>
Paris vacation
Andaman Island Retreat
Using ElementTree, you can easily modify and update the elements and values of the XML file, unlike miniDOM and SAX. Let’s check how in the next section.
How to modify XML files with ElementTree?
Let’s say it is time for the Christmas holidays and the agency wants to double the package costs. ElementTree provides a set() function, which we can use to update the values of elements. In the below code, I have accessed the price of each package through iter() function and manipulated the prices. You can use the write() function to write a new XML file with updated elements.
for price in root.iter('price'):
new_price = int(price.text)*2
price.text = str(new_price)
price.set('updated', 'yes')
tree.write('christmas_packages.xml')You should be able to find an output file like the one in the below image. If you recall, the prices for Paris Vacation and Hawaii Adventure are $3000 and $4000 in the original file.
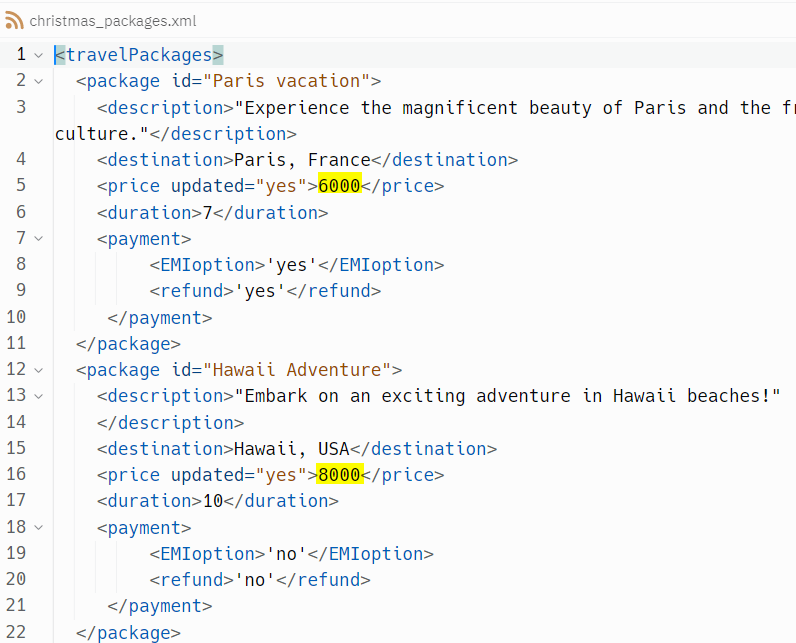
But, what if we want to add a new tag <stay> to the Andaman package to denote that the stay offered is ‘Premium private villa’. The SubElement() function of ElementTree lets us add new subtags as per need, as demonstrated in the below snippet. You should pass the element you want to modify and the new tag as parameters to the function.
ET.SubElement(root[3], 'stay')
for x in root.iter('stay'):
resort = 'Premium Private Villa'
x.text = str(resort)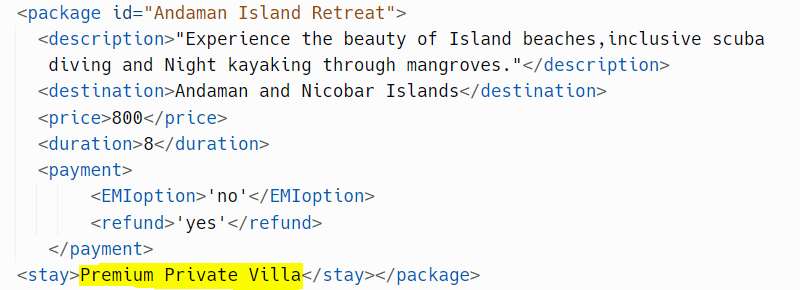
Hope you got the results too! The package also provides pop() function, through which you can delete attributes and subelements if they are unnecessary.
Simple API for XML (SAX)
SAX is another python parser, which overcomes the shortcoming of miniDOM by reading the document sequentially. It does not load the entire tree into its memory, and also allows you to discard items, reducing memory usage.
First, let us create a SAX parser object and register callback functions for the different events that you want to handle in the XML document. To do this, I define a custom TravelPackageHandler class as shown below by sub-classing SAX’s ContentHandler.
import xml.sax
# Define a custom SAX ContentHandler class to handle events
class TravelPackageHandler(xml.sax.ContentHandler):
def __init__(self):
self.packages = []
self.current_package = {}
self.current_element = ""
self.current_payment = {} def startElement(self, name, attrs):
self.current_element = name
if name == "package":
self.current_package = {"id": attrs.getValue("id")} def characters(self, content):
if self.current_element in ["description", "destination", "price", "duration", "EMIoption", "refund"]:
self.current_package[self.current_element] = content.strip()
if self.current_element == "payment":
self.current_payment = {} def endElement(self, name):
if name == "package":
self.current_package["payment"] = self.current_payment
self.packages.append(self.current_package)
if name == "payment":
self.current_package["payment"] = self.current_payment def startElementNS(self, name, qname, attrs):
pass def endElementNS(self, name, qname):
passIn the above snippet, the startElement(), characters(), and endElement() methods are used to extract the data from the XML elements and attributes. As the SAX parser reads through the document, it triggers the registered callback functions for each event that it encounters. For example, if it encounters the start of a new element, it calls the startElement() function. Now, let’s use our custom handler to get the various package IDs parsing our example XML file.
# Create a SAX parser object
parser = xml.sax.make_parser()
handler = TravelPackageHandler()
parser.setContentHandler(handler)
parser.parse("travel_pckgs.xml")
for package in handler.packages:
print(f'Package: {package["id"]}')Output >>
Package: Paris vacation
Package: Hawaii Adventure
Package: Italian Getaway
Package: Andaman Island Retreat
SAX can be used for large files and streaming due to its efficiency. But, it is inconvenient while working with deeply nested elements. What if you want to access any random tree node? As it doesn’t support random access, the parser will have to read through the entire document sequentially to access a specific element.
Sync all your double entries with Nanonets. Keep all your accounts balanced, 24×7. Set up your accounting processes in <15 minutes. See how.
Streaming Pull Parser for XML
This is the pulldom Python library that provides a streaming pull parser API with a DOM-like interface.
How does it work?
It processes the XML data in a “pull” manner. That is, you explicitly request the parser to provide the next event (e.g., start element, end element, text, etc.) in the XML data.
The syntax is familiar to what we have seen in the previous libraries. In the below code, I demonstrate how to import the library and use it to print the tours which have a duration of 4 days or more, and also provide a refund on cancellation.
from xml.dom.pulldom import parse
events = parse("travel_pckgs.xml")
for event, node in events:
if event == pulldom.START_ELEMENT and node.tagName == 'package':
duration = int(node.getElementsByTagName('duration')[0].firstChild.data)
refund = node.getElementsByTagName('refund')[0].firstChild.data.strip("'")
if duration > 4 and refund == 'yes':
print(f"Package: {node.getAttribute('id')}")
print(f"Duration: {duration}")
print(f"Refund: {refund}")You should get output like:
Package: Paris vacation
Duration: 7
Refund: yes
Package: Andaman Island Retreat
Duration: 8
Refund: yes
Check the results! The pull parser combines a few features from miniDOM and SAX, making it relatively efficient.
Summary
I’m sure you have a good grasp of the various parsers available in python by now. Knowing when to choose which parser to save time and resources is equally important. Among all the parsers we saw, ElementTree provides maximum compatibility with XPath expressions that help perform complex queries. Minidom has an easy-to-use interface and can be chosen for dealing with small files, but is too slow in case of large files. At the same time, SAX is used in situations where the XML file is constantly updated, as in the case of real-time Machine learning.
One alternative to parse your files is using automate parsing tools like Nanonets. Nanonets can help you extract data from any kind of document in seconds without writing a single line of code.
Optimize your business performance, save costs and boost growth. Find out how Nanonets’ use cases can apply to your product.
Source: https://nanonets.com/blog/parse-xml-files-using-python/
