This is a guest post by Nan Zhu, Tech Lead Manager, SafeGraph, and Dave Thibault, Sr. Solutions Architect – AWS
SafeGraph is a geospatial data company that curates over 41 million global points of interest (POIs) with detailed attributes, such as brand affiliation, advanced category tagging, and open hours, as well as how people interact with those places. We use Apache Spark as our main data processing engine and have over 1,000 Spark applications running over massive amounts of data every day. These Spark applications implement our business logic ranging from data transformation, machine learning (ML) model inference, to operational tasks.
SafeGraph found itself with a less-than-optimal Spark environment with their incumbent Spark vendor. Their costs were climbing. Their jobs would suffer frequent retries from Spot Instance termination. Developers spent too much time troubleshooting and changing job configurations and not enough time shipping business value code. SafeGraph needed to control costs, improve developer iteration speed, and improve job reliability. Ultimately, SafeGraph chose Amazon EMR on Amazon EKS to meet their needs and realized 50% savings relative to their previous Spark managed service vendor.
If building Spark applications for our product is like cutting a tree, having a sharp saw becomes crucial. The Spark platform is the saw. The following figure highlights the engineering workflow when working with Spark, and the Spark platform should support and optimize each action in the workflow. The engineers usually start with writing and building the Spark application code, then submit the application to the computing infrastructure, and finally close the loop by debugging the Spark applications. Additionally, platform and infrastructure teams need to continually operate and optimize the three steps in the engineering workflow.
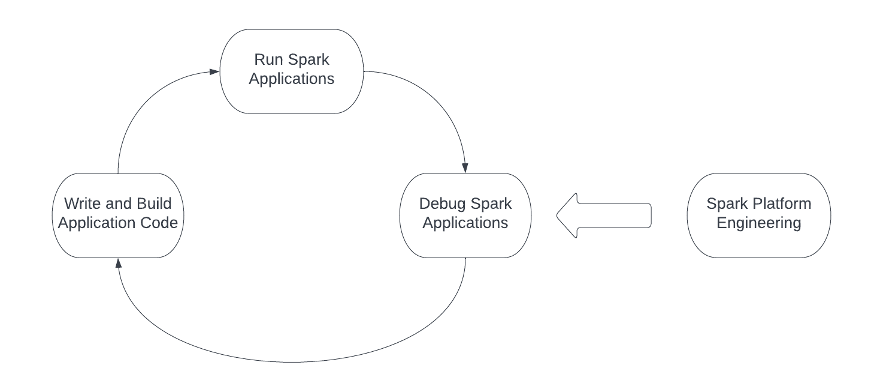
There are various challenges involved in each action when building a Spark platform:
- Reliable dependency management – A complicated Spark application usually brings many dependencies. To run a Spark application, we need to identify all dependencies, resolve any conflicts, pack dependent libraries reliably, and ship them to the Spark cluster. Dependency management is one of the biggest challenges for engineers, especially when they work with PySpark applications.
- Reliable computing infrastructure – The reliability of the computing infrastructure hosting Spark applications is the foundation of the whole Spark platform. Unstable resource provisioning will not only cause negative impact over engineering efficiency, but it will also increase infrastructure costs due to reruns of the Spark applications.
- Convenient debugging tools for Spark applications – The debugging tooling plays a key role for engineers to iterate fast on Spark applications. Performant access to the Spark History Server (SHS) is a must for developer iteration speed. Conversely, poor SHS performance slows developers and increases the cost of goods sold for software companies.
- Manageable Spark infrastructure – A successful Spark platform engineering involves multiple aspects, such as Spark distribution version management, computing resource SKU management and optimization, and more. It largely depends on whether the Spark service vendors provide the right foundation for platform teams to use. The wrong abstraction over distribution version and computing resources, for example, could significantly reduce the ROI of platform engineering.
At SafeGraph, we experienced all of the aforementioned challenges. To resolve them, we explored the marketplace and found that building a new Spark platform on top of EMR on EKS was the solution to our roadblocks. In this post, we share our journey of building our latest Spark platform and how EMR on EKS serves as a robust and efficient foundation for it.
Reliable Python dependency management
One of the biggest challenges for our users to write and build Spark application code is the struggle of managing dependencies reliably, especially for PySpark applications. Most of our ML-related Spark applications are built with PySpark. With our previous Spark service vendor, the only supported way to manage Python dependencies was via a wheel file. Despite its popularity, wheel-based dependency management is fragile. The following figure shows two types of reliability issues faced with wheel-based dependency management:
- Unpinned direct dependency – If the .whl file doesn’t pinpoint the version of a certain direct dependency, Pandas in this example, it will always pull the latest version from upstream, which may potentially contain a breaking change and take down our Spark applications.
- Unpinned transitive dependency – The second type of reliability issue is more out of our control. Even though we pinned the direct dependency version when building the .whl file, the direct dependency itself could miss pinpointing the transitive dependencies’ versions (MLFlow in this example). The direct dependency in this case always pulls the latest versions of these transitive dependencies that potentially contain breaking changes and may take down our pipelines.

The other issue we encountered was the unnecessary installation of all Python packages referred by the wheel files for every Spark application initialization. With our previous setup, we needed to run the installation script to install wheel files for every Spark application upon starting even if there is no dependency change. This installation prolongs the Spark application start time from 3–4 minutes to at least 7–8 minutes. The slowdown is frustrating especially when our engineers are actively iterating over changes.
Moving to EMR on EKS enables us to use pex (Python EXecutable) to manage Python dependencies. A .pex file packs all dependencies (including direct and transitive) of a PySpark application in an executable Python environment in the spirit of virtual environments.
The following figure shows the file structure after converting the wheel file illustrated earlier to a .pex file. Compared to the wheel-based workflow, we don’t have transitive dependency pulling or auto-latest version fetching anymore. All versions of dependencies are fixed as x.y.z, a.b.c, and so on when building the .pex file. Given a .pex file, all dependencies are fixed so that we don’t suffer from the slowness or fragility issues in a wheel-based dependency management anymore. The cost of building a .pex file is a one-off cost, too.

Reliable and efficient resource provisioning
Resource provisioning is the process for the Spark platform to get computing resources for Spark applications, and is the foundation for the whole Spark platform. When building a Spark platform in the cloud, using Spot Instances for cost optimization makes resource provisioning even more challenging. Spot Instances are spare compute capacity available to you at a savings of up to 90% off compared to On-Demand prices. However, when the demand for certain instance types grows suddenly, Spot Instance termination can happen to prioritize meeting those demands. Because of these terminations, we saw several challenges in our earlier version of Spark platform:
- Unreliable Spark applications – When the Spot Instance termination happened, the runtime of Spark applications got prolonged significantly due to the retried compute stages.
- Compromised developer experience – The unstable supply of Spot Instances caused frustration among engineers and slowed our development iterations because of the unpredictable performance and low success rate of Spark applications.
- Expensive infrastructure bill – Our cloud infrastructure bill increased significantly due to the retry of jobs. We had to buy more expensive Amazon Elastic Compute Cloud (Amazon EC2) instances with higher capacity and run in multiple Availability Zones to mitigate issues but in turn paid for the high cost of cross-Availability Zone traffic.
Spark Service Providers (SSPs) like EMR on EKS or other third-party software products serve as the intermediate between users and Spot Instance pools, and play a key role to ensure the sufficient supply of Spot Instances. As shown in the following figure, users launch Spark jobs with job orchestrators, notebooks, or services via SSPs. The SSP implements their internal functionality to access the unused instances in the Spot Instance pool in cloud services like AWS. One of the best practices of using Spot Instances is to diversify instance types (for more information, see Cost Optimization using EC2 Spot Instances). Specifically, there are two key features for a SSP to achieve instance diversification:
- The SSP should be able to access all types of instances in the Spot Instance pool in AWS
- The SSP should provide functionality for users to use as many instance types as possible when launching Spark applications
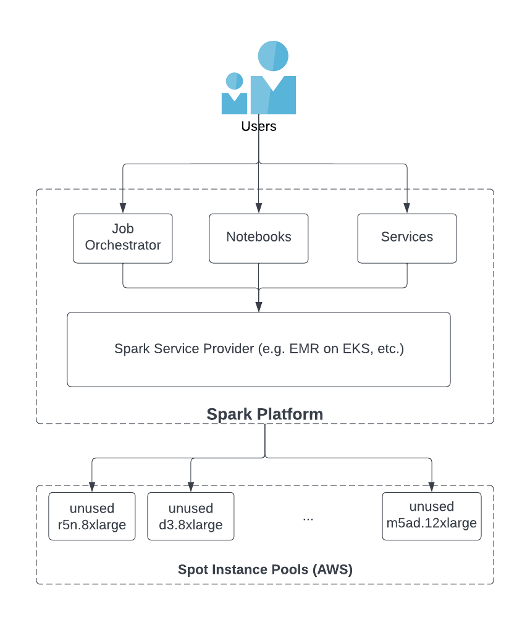
Our last SSP doesn’t provide the expected solution to these two points. They only support a limited set of Spot Instance types and by default, allow only a single Spot Instance type to be selected when launching Spark jobs. As a result, each Spark application only runs with a small capacity of Spot Instances and is vulnerable to Spot Instance terminations.
EMR on EKS uses Amazon Elastic Kubernetes Service (Amazon EKS) for accessing Spot Instances in AWS. Amazon EKS supports all available EC2 instance types, bringing a much higher capacity pool to us. We use the features of Amazon EKS managed node groups and node selectors and taints to assign each Spark application to a node group that is made of multiple instance types. After moving to EMR on EKS, we observed the following benefits:
- Spot Instance termination was less frequent and our Spark applications’ runtime became shorter and stayed stable.
- Engineers were able to iterate faster as they saw improvement in the predictability of application behaviors.
- The infrastructure costs dropped significantly because we no longer needed costly workarounds and, simultaneously, we had a sophisticated selection of instances in each node group of Amazon EKS. We were able to save approximately 50% of computing costs without the workarounds like running in multiple Availability Zones and simultaneously provide the expected level of reliability.
Smooth debugging experience
An infrastructure that supports engineers conveniently debugging the Spark application is critical to close the loop of our engineering workflow. Apache Spark uses event logs to record the activities of a Spark application, such as task start and finish. These events are formatted in JSON and are used by SHS to rerender the UI of Spark applications. Engineers can access SHS to debug task failure reasons or performance issues.
The major challenge for engineers in SafeGraph was the scalability issue in SHS. As shown in the left part of the following figure, our previous SSP forced all engineers to share the same SHS instance. As a result, SHS was under intense resource pressure due to many engineers accessing at the same time for debugging their applications, or if a Spark application had a large event log to be rendered. Prior to moving to EMR on EKS, we frequently experienced either slowness of SHS or SHS crashed completely.
As shown in the following figure, for every request to view Spark history UI, EMR on EKS starts an independent SHS instance container in an AWS-managed environment. The benefit of this architecture is two-fold:
- Different users and Spark applications won’t compete for SHS resources anymore. Therefore, we never experience slowness or crashes of SHS.
- All SHS containers are managed by AWS; users don’t need pay additional financial or operational costs to enjoy the scalable architecture.

Manageable Spark platform
As shown in the engineering workflow, building a Spark platform is not a one-off effort, and platform teams need to manage the Spark platform and keep optimizing each step in the engineer development workflow. The role of the SSP should provide the right facilities to ease operational burden as much as possible. Although there are many types of operational tasks, we focus on two of them in this post: computing resource SKU management and Spark distro version management.
Computing resource SKU management refers to the design and process for a Spark platform to allow users to choose different sizes of computing instances. Such a design and process would largely rely on the relevant functionality implemented from SSPs.
The following figure shows the SKU management with our previous SSP.

The following figure shows SKU management with EMR on EKS.

With our previous SSP, job configuration only allowed explicitly specifying a single Spot Instance type, and if that type ran out of Spot capacity, the job switched to On-Demand or fell into reliability issues. This left platform engineers with the choice of changing the settings across the fleet of Spark jobs or risking unwanted surprises for their budget and cost of goods sold.
EMR on EKS makes it much easier for the platform team to manage computing SKUs. In SafeGraph, we embedded a Spark service client between users and EMR on EKS. The Spark service client exposes only different tiers of resources to users (such as small, medium, and large). Each tier is mapped to a certain node group configured in Amazon EKS. This design brings the following benefits:
- In the case of prices and capacity changes, it’s easy for us to update configurations in node groups and keep it abstracted from users. Users don’t change anything, or even feel it, and continue to enjoy the stable resource provisioning while we keep costs and operational overhead as low as possible.
- When choosing the right resources for the Spark application, end-users don’t need to do any guess work because it’s easy to choose with simplified configuration.
Improved Spark distro release management is the other benefit we gain from EMR on EKS. Prior to using EMR on EKS, we suffered from the non-transparent release of Spark distro in our SSP. Every 1–2 months, there is a new patched version of Spark distro released to users. These versions are all exposed to users via their UI. This resulted in engineers choosing various versions of distro, some of which hadn’t been tested with our internal tools. It significantly increased the breaking rate of our pipelines, internal systems, and the support burden of platform teams. We expect that the risk from releases of Spark distros should be minimum and transparent to users with an EMR on EKS architecture.
EMR on EKS follows the best practices with a stable base Docker image containing a fixed version of Spark distro. For any change of Spark distro, we have to explicitly rebuild and roll out the Docker image. With EMR on EKS, we can keep a new version of Spark distro hidden from users before testing it with our internal toolings and systems and make a formal release.
Conclusion
In this post, we shared our journey building a Spark platform on top of EMR on EKS. EMR on EKS as the SSP serves as a strong foundation of our Spark platform. With EMR on EKS, we were able to resolve challenges ranging from dependency management, resource provisioning, and debugging experience, and also significantly reduce our computing cost by 50% due to higher availability of Spot Instance types and sizes.
We hope this post could share some insights to the community when choosing the right SSP for your business. Learn more about EMR on EKS, including benefits, features, and how to get started.
About the Authors
 Nan Zhu is the Tech Lead Manager of the platform team in SafeGraph. He leads the team to build a broad range of infrastructure and internal toolings to improve the reliability, efficiency and productivity of the SafeGraph engineering process, e.g. internal Spark ecosystem, metrics store and CI/CD for large mono repos, etc. He is also involved in multiple open source projects like Apache Spark, Apache Iceberg, Gluten, etc.
Nan Zhu is the Tech Lead Manager of the platform team in SafeGraph. He leads the team to build a broad range of infrastructure and internal toolings to improve the reliability, efficiency and productivity of the SafeGraph engineering process, e.g. internal Spark ecosystem, metrics store and CI/CD for large mono repos, etc. He is also involved in multiple open source projects like Apache Spark, Apache Iceberg, Gluten, etc.
 Dave Thibault is a Sr. Solutions Architect serving AWS’s independent software vendor (ISV) customers. He’s passionate about building with serverless technologies, machine learning, and accelerating his AWS customers’ business success. Prior to joining AWS, Dave spent 17 years in life sciences companies doing IT and informatics for research, development, and clinical manufacturing groups. He also enjoys snowboarding, plein air oil painting, and spending time with his family.
Dave Thibault is a Sr. Solutions Architect serving AWS’s independent software vendor (ISV) customers. He’s passionate about building with serverless technologies, machine learning, and accelerating his AWS customers’ business success. Prior to joining AWS, Dave spent 17 years in life sciences companies doing IT and informatics for research, development, and clinical manufacturing groups. He also enjoys snowboarding, plein air oil painting, and spending time with his family.
