This post is co-written with Suhyoung Kim, General Manager at KakaoGames Data Analytics Lab.
Kakao Games is a top video game publisher and developer headquartered in South Korea. It specializes in developing and publishing games on PC, mobile, and virtual reality (VR) serving globally. In order to maximize its players’ experience and improve the efficiency of operations and marketing, they are continuously adding new in-game items and providing promotions to their players. The result of these events can be evaluated afterwards so that they make better decisions in the future.
However, this approach is reactive. If we can forecast lifetime value (LTV), we can take a proactive approach. In other words, these activities can be planned and run based on the forecasted LTV, which determines the players’ values through their lifetime in the game. With this proactive approach, Kakao Games can launch the right events at the right time. If the forecasted LTV for some players is decreasing, this means that the players are likely to leave soon. Kakao Games can then create a promotional event not to leave the game. This makes it important to accurately forecast the LTV of their players. LTV is the measurement adopted by not only gaming companies but also any kind of service with long-term customer engagement. Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV.
In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
We chose one of the most popular games of Kakao Games, ODIN, as the target game for the project. ODIN is a popular massively multiplayer online roleplaying game (MMORPG) for PC and mobile devices published and operated by Kakao Games. It was launched in June 2021 and has been ranked within the top three in revenue in Korea.

Challenges
In this section, we discuss challenges around various data sources, data drift caused by internal or external events, and solution reusability. These challenges are typically faced when we implement ML solutions and deploy them into a production environment.
Player behavior affected by internal and external events
It’s challenging to forecast the LTV accurately, because there are many dynamic factors affecting player behavior. These include game promotions, newly added items, holidays, banning accounts for abuse or illegal play, or unexpected external events like sport events or severe weather conditions. This means that the model working this month might not work well next month.
We can utilize external events as ML features along with the game-related logs and data. For example, Amazon Forecast supports related time series data like weather, prices, economic indicators, or promotions to reflect internal and external related events. Another approach is to refresh ML models regularly when data drift is observed. For our solution, we chose the latter method because the related event data wasn’t available and we weren’t sure how reliable the existing data was.
Continuous ML model retraining is one method to overcome this challenge by relearning from the most recent data. This requires not only well-designed features and ML architecture, but also data preparation and ML pipelines that can automate the retraining process. Otherwise, the ML solution can’t be efficiently operated in the production environment due to the complexity and poor repeatability.
It’s not sufficient to retrain the model using the latest training dataset. The retrained model might not give a more accurate forecasting result than the existing one, so we can’t simply replace the model with the new one without any evaluation. We need to be able to go back to the previous model if the new model starts to underperform for some reason.
To solve this problem, we had to design a strong data pipeline to create the ML features from the raw data and MLOps.
Multiple data sources
ODIN is an MMORPG where the game players interact with each other, and there are various events such as level-up, item purchase, and gold (game money) hunting. It produces about 300 GB logs every day from its more than 10 million players across the world. The gaming logs are of different types, such as player login, player activity, player purchases, and player level-ups. These types of data are historical raw data from an ML perspective. For example, each log is written in the format of timestamp, user ID, and event information. The interval of logs is not uniform. Also, there is static data describing the players such as their age and registration date, which is non-historical data. LTV prediction modeling requires these two types of data as its input because they complement each other to represent the player’s characteristics and behavior.
For this solution, we decided to define the tabular dataset combining the historical features with the fixed number of aggregated steps along with the static player features. The aggregated historical features are generated through multiple steps from the number of game logs, which are stored in Amazon Athena tables. In addition to the challenge of defining the features for the ML model, it’s critical to automate the feature generation process so that we can get ML features from the raw data for ML inference and model retraining.
To solve this problem, we build an extract, transform, and load (ETL) pipeline that can be run automatically and repeatedly for training and inference dataset creation.
Scalability to other games
Kakao Games has other games with long-term player engagements just like ODIN. Naturally, LTV prediction benefits those games as well. Because most of the games share similar log types, they want to reuse this ML solution to other games. We can fulfill this requirement by using the common log and attributes among different games when we design the ML model. But there is still an engineering challenge. The ETL pipeline, MLOps pipeline, and ML inference should be rebuilt in a different AWS account. Manual deployment of this complex solution isn’t scalable and the deployed solution is hard to maintain.
To solve this problem, we make the ML solution auto-deployable with a few configuration changes.
Solution overview
The ML solution for LTV forecasting is composed of four components: the training dataset ETL pipeline, MLOps pipeline, inference dataset ETL pipeline, and ML batch inference.
The training and inference ETL pipeline creates ML features from the game logs and the player’s metadata stored in Athena tables, and stores the resulting feature data in an Amazon Simple Storage Service (Amazon S3) bucket. ETL requires multiple transformation steps, and the workflow is implemented using AWS Glue. The MLOps trains ML models, evaluates the trained model against the existing model, and then registers the trained model to the model registry if it outperforms the existing model. These are all implemented as a single ML pipeline using Amazon SageMaker Pipelines, and all the ML trainings are managed via Amazon SageMaker Experiments. With SageMaker Experiments, ML engineers can find which training and evaluation datasets, hyperparameters, and configurations were used for each ML model during the training or later. ML engineers no longer need to manage this training metadata separately.
The last component is the ML batch inference, which is run regularly to predict LTV for the next couple of weeks.
The following figure shows how these components work together as a single ML solution.
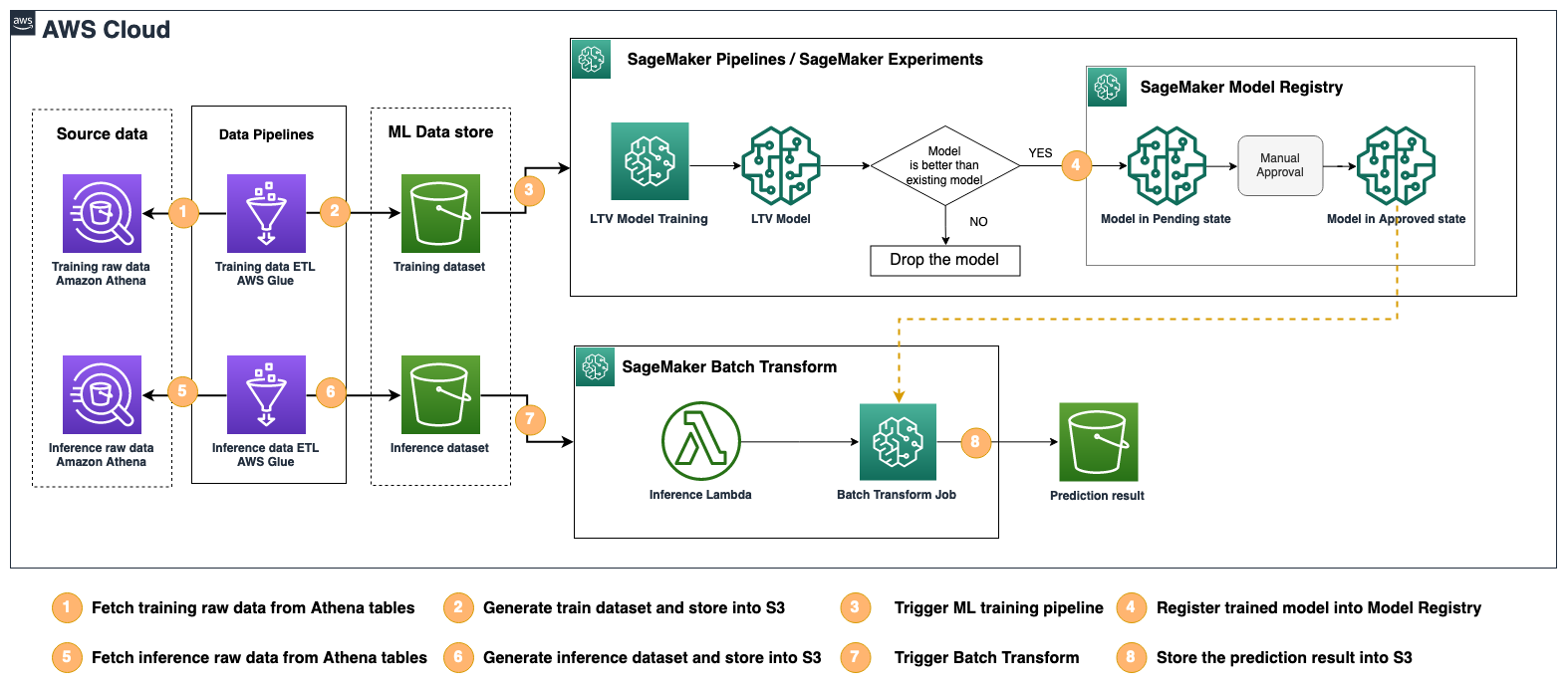
The solution architecture has been implemented using the AWS Cloud Development Kit (AWS CDK) to promote infrastructure as code (IaC), making it easy to version control and deploy the solution across different AWS accounts and Regions
In the following sections, we discuss each component in more detail.
Data pipeline for ML feature generation
Game logs stored in Athena backed by Amazon S3 go through the ETL pipelines created as Python shell jobs in AWS Glue. It enables running Python scripts with AWS Glue for feature exaction to generate the training-ready dataset. Corresponding tables in each phase are created in Athena. We use AWS Glue for running the ETL pipeline due to its serverless architecture and flexibility in generating different versions of the dataset by passing in various start and end dates. Refer to Accessing parameters using getResolvedOptions to learn more about how to pass the parameters to an AWS Glue job. With this method, the dataset can be created to cover a period of as short as 4 weeks, supporting the game in its early stages. For instance, the input start date and prediction start date for each version of dataset are parsed via the following code:
AWS Glue jobs are designed and divided into different stages and triggered sequentially. Each job is configured to take in positional and key-value pair arguments to run customized ETL pipelines. One key parameter is the start and end date of the data that is used in training. This is because the start and end date of data likely span different holidays, and serve as a direct factor in determining the length of dataset. To observe this parameter’s impact on model performances, we created nine different dataset versions (with different start dates and length of training period).
Specifically, we created dataset versions with different start dates (shifted by 4 weeks) and different training periods (12 weeks, 16 weeks, 20 weeks, 24 weeks, and 28 weeks) in nine Athena databases backed by Amazon S3. Each version of the dataset contains the features describing player characteristics and in-game purchase activity time series data.
ML model
We selected AutoGluon for model training implemented with SageMaker pipelines. AutoGluon is a toolkit for automated machine learning (AutoML). It enables easy-to-use and easy-to-extend AutoML with a focus on automated stack ensembling, deep learning, and real-world applications spanning image, text, and tabular data.
You can use AutoGluon standalone to train ML models or in conjunction with Amazon SageMaker Autopilot, a feature of SageMaker that provides a fully managed environment for training and deploying ML models.
In general, you should use AutoGluon with Autopilot if you want to take advantage of the fully managed environment provided by SageMaker, including features such as automatic scaling and resource management, as well as easy deployment of trained models. This can be especially useful if you’re new to ML and want to focus on training and evaluating models without worrying about the underlying infrastructure.
You can also use AutoGluon standalone when you want to train ML models in a customized way. In our case, we used AutoGluon with SageMaker to realize a two-stage prediction, including churn classification and lifetime value regression. In this case, the players that stopped purchasing game items are considered as having churned.
Let’s talk about the modeling approach for LTV prediction and the effectiveness of the model retraining against the data drift symptom, which means the internal or external events that change a player’s purchase pattern.
First, the modeling processes were separated into two stages, including a binary classification (classifying a player as churned or not) and a regression model that was trained to predict the LTV value for non-churned players:
- Stage 1 – Target values for LTV are converted into a binary label,
LTV = 0andLTV > 0. AutoGluon TabularPredictor is trained to maximize F1 score. - Stage 2 – A regression model using AutoGluon TabularPredictor is used to train the model on users with
LTV > 0for actual LTV regression.
During the model testing phase, the test data goes through the two models sequentially:
- Stage 1 – The binary classification model runs on test data to get the binary prediction 0 (user having
LTV = 0, churned) or 1 (user havingLTV > 0, not churned). - Stage 2 – Players predicted with
LTV > 0go through the regression model to get the actual LTV value predicted. Combined with the user predicted as havingLTV = 0, the final LTV prediction result is generated.
Model artifacts associated with the training configurations for each experiment and for each version of dataset are stored in an S3 bucket after the training, and also registered to the SageMaker Model Registry within the SageMaker Pipelines run.
To test if there is any data drift due to using the same model trained on the dataset v1 (12 weeks starting from October), we run inference on dataset v1, v2 (starting time shifted forward by 4 weeks), v3 (shifted forward by 8 weeks), and so on for v4 and v5. The following table summarizes model performance. The metric used for comparison is minmax score, whose range is 0–1. It gives a higher number when the LTV prediction is closer to the true LTV value.
| Dataset Version | Minmax Score | Difference with v1 |
| v1 | 0.68756 | – |
| v2 | 0.65283 | -0.03473 |
| v3 | 0.66173 | -0.02584 |
| v4 | 0.69633 | 0.00877 |
| v5 | 0.71533 | 0.02777 |
A performance drop is seen on dataset v2 and v3, which is consistent with the analysis performed on various modeling approaches having decreasing performance on dataset v2 and v3. For v4 and v5, the model shows equivalent performance, and even shows a slight improvement on v5 without model retraining. However, when comparing model v1 performance on dataset v5 (0.71533) vs. model v5 performance on dataset v5 (0.7599), model retraining is improving performance significantly.
Training pipeline
SageMaker Pipelines provides easy ways to compose, manage, and reuse ML workflows; select the best models for deploying into production; track the models automatically; and integrate CI/CD into ML pipelines.
In the training step, a SageMaker Estimator is constructed with the following code. Unlike the normal SageMaker Estimator to create a training job, we pass a SageMaker pipeline session to SageMaker_session instead of a SageMaker session:
The base image is retrieved by the following code:
The trained model goes through the evaluation process, where the target metric is minmax. A score larger than the current best LTV minmax score will lead to a model register step, whereas a lower LTV minmax score won’t lead to the current registered model version being updated. The model evaluation on the holdout test dataset is implemented as a SageMaker Processing job.
The evaluation step is defined by the following code:
When the model evaluation is complete, we need to compare the evaluation result (minmax) with the existing model’s performance. We define another pipeline step, step_cond.
With all the necessary steps defined, the ML pipeline can be constructed and run with the following code:
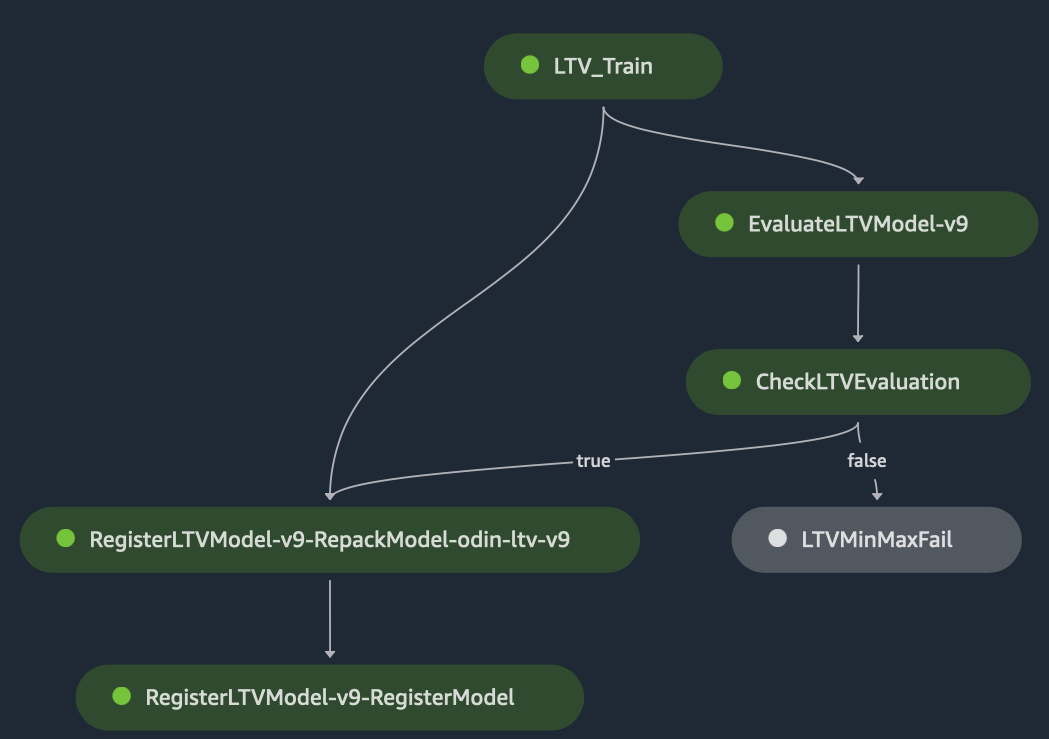
The whole workflow is trackable and visualized in Amazon SageMaker Studio, as shown in the following graph. The ML training jobs are tracked by the SageMaker Experiment automatically so that you can find the ML training configuration, hyperparameters, dataset, and trained model of each training job. Choose each of the modules, logs, parameters, output, and so on to examine them in detail.
Automated batch inference
In the case of LTV prediction, batch inference is preferred to real-time inference because the predicted LTV is used for the offline downstream tasks normally. Just like creating ML features from the training dataset through the multi-step ETL, we have to create the ML features as an input to the LTV prediction model. We reuse the same workflow of AWS Glue to convert the players’ data into the ML features, but the data split and the label generation are not performed. The resulting ML feature is stored in the designated S3 bucket, which is monitored by an AWS Lambda trigger. When the ML feature file is dropped into the S3 bucket, the Lambda function runs automatically, which starts the SageMaker batch transform job using the latest and approved LTV model found in the SageMaker Model Registry. When the batch transform is complete, the output or predicted LTV values for each player are saved to the S3 bucket so that any downstream task can pick up the result. This architecture is described in the following diagram.

With this pipeline combining the ETL task and the batch inference, the LTV prediction is done simply running the AWS Glue ETL workflow regularly, such as once a week or once a month. AWS Glue and SageMaker manage their underlying resources, which means that this pipeline doesn’t require you to keep any resource running all the time. Therefore, this architecture using managed services is cost effective for batch tasks.
Deployable solution using the AWS CDK
The ML pipeline itself is defined and run using Pipelines, but the data pipeline and the ML model inference code including the Lambda function are out of the scope of Pipelines. To make this solution deployable so that we can apply this to other games, we defined the data pipeline and ML model inference using the AWS CDK. This way, the engineering team and data science team have the flexibility to manage, update, and control the whole ML solution without having to manage the infrastructure manually using the AWS Management Console.
Conclusion
In this post, we discussed how we could solve data drift and complex ETL challenges by building an automated data pipeline and ML pipeline utilizing managed services such as AWS Glue and SageMaker, and how to make it a scalable and repeatable ML solution to be adopted by other games using the AWS CDK.
“In this era, games are more than just content. They bring people together and have boundless potential and value when it comes to enjoying our lives. At Kakao Games, we dream of a world filled with games anyone can easily enjoy. We strive to create experiences where players want to stay playing and create bonds through community. The MLSL team helped us build a scalable LTV prediction ML solution using AutoGluon for AutoML, Amazon SageMaker for MLOps, and AWS Glue for data pipeline. This solution automates the model retraining for data or game changes, and can easily be deployed to other games via the AWS CDK. This solution helps us optimize our business processes, which in turn helps us stay ahead in the game.”
– SuHyung Kim, Head of Data Analytics Lab, Kakao Games.
To learn more about related features of SageMaker and the AWS CDK, check out the following:
Amazon ML Solutions Lab
The Amazon ML Solutions Lab pairs your team with ML experts to help you identify and implement your organization’s highest-value ML opportunities. If you want to accelerate your use of ML in your products and processes, please contact the Amazon ML Solutions Lab.
About the Authors
 Suhyoung Kim is a General Manager at KakaoGames Data Analytics Lab. He is responsible for gathering and analyzing data, and especially concern for the economy of online games.
Suhyoung Kim is a General Manager at KakaoGames Data Analytics Lab. He is responsible for gathering and analyzing data, and especially concern for the economy of online games.
 Muhyun Kim is a data scientist at Amazon Machine Learning Solutions Lab. He solves customer’s various business problems by applying machine learning and deep learning, and also helps them gets skilled.
Muhyun Kim is a data scientist at Amazon Machine Learning Solutions Lab. He solves customer’s various business problems by applying machine learning and deep learning, and also helps them gets skilled.
 Sheldon Liu is a Data Scientist at Amazon Machine Learning Solutions Lab. As an experienced machine learning professional skilled in architecting scalable and reliable solutions, he works with enterprise customers to address their business problems and deliver effective ML solutions.
Sheldon Liu is a Data Scientist at Amazon Machine Learning Solutions Lab. As an experienced machine learning professional skilled in architecting scalable and reliable solutions, he works with enterprise customers to address their business problems and deliver effective ML solutions.
 Alex Chirayath is a Senior Machine Learning Engineer at the Amazon ML Solutions Lab. He leads teams of data scientists and engineers to build AI applications to address business needs.
Alex Chirayath is a Senior Machine Learning Engineer at the Amazon ML Solutions Lab. He leads teams of data scientists and engineers to build AI applications to address business needs.
 Gonsoo Moon, AI/ML Specialist Solutions Architect at AWS, has worked together customers to solve their ML problems using AWS AI/ML services. In the past, he had experience in developing machine learning services in the manufacture industry as well as in a large scale of service development, data analysis and system development in the portal and gaming industry. In his spare time, Gonsoo takes a walk and plays with children.
Gonsoo Moon, AI/ML Specialist Solutions Architect at AWS, has worked together customers to solve their ML problems using AWS AI/ML services. In the past, he had experience in developing machine learning services in the manufacture industry as well as in a large scale of service development, data analysis and system development in the portal and gaming industry. In his spare time, Gonsoo takes a walk and plays with children.
