Data is the lifeline of all online businesses and the way we interact.
Every day, we create roughly 2.5 quintillion bytes of data. That’s a lot. But what is surprising is that 90% of that data is unstructured.
It does not have any particular structure. So in order to make sense of the data, we really need to understand how to deal with unstructured data.
Let’s deep dive into unstructured data without further ado.
What is Unstructured Data?
Everything in this digital world is composed of data. Data can be of two formats, either it can follow a proper structure or it would not.
Any information that is not arranged into any sequence or scheme or any specific structure that makes it easy to read for others is called unstructured data.
Unstructured data has no structure or format to make it easily recognizable. Unstructured data is highly text-based like data, facts open-ended survey responses but it also can be nontextual like images, audio, or video.
Read more: How to extract data from PDF?
What are the examples of unstructured data?
When you think of data, think of any kind of data that does not have a repeating or recognizable pattern, and that would be unstructured data. It can be textual, nontextual, human, or machine-generated. Here are some examples of unstructured data :
Text Data
The data that is available in an email or written form is called text data. Text messages, written documents, word, PDFs, and other files, of them, are an example of unstructured data.
Multi-media messages
One type of unstructured data is multimedia messages. Multi-media data comprises images (JPEG, PNG, GIF), audio, or video format. Multimedia messages are a mix of complex code that does not have a similar pattern.
All the images, videos, or audio files can be encrypted binary codes which follow no pattern, and therefore are unstructured data. What do you see here?

Well, it is actually an image of a red car.

The images and pictures need observation to understand and their data is not completely composed, that’s why this is called the unstructured data.
Website content
All the websites are filled with any information that is available in the form of long paragraphs, scattered, and disorganized forms. This is a sort of data with valuable information but still, it is not worthy because the proper composition of data is required.
Sensor Data – IoT devices
The Internet of things is a physical device that collects information about its surrounding and sends the data back to the cloud. IoT devices send back sensitive sensor data which can be unstructured. Examples of IoT devices sending senor data could be traffic monitoring devices, music devices like Alexa, Google Home, etc.
Email is widely used by businesses as one of the primary channels to communicate. Emails can be classified as semi-structured or unstructured. There are many parsing tools available that scrape the email information to understand the details.
Business Documents
Businesses deal with documents of various types, like PDFs, emails, invoices, orders, and more. All the documents have different structures. In order to extract data from PDFs, and other paper-based documents, businesses can use intelligent document processing software like Nanonets.
10,000+ users use Nanonets to convert unstructured data into structured data with 98%+ accuracy. Give it a try?
What is the difference between structured and unstructured data?
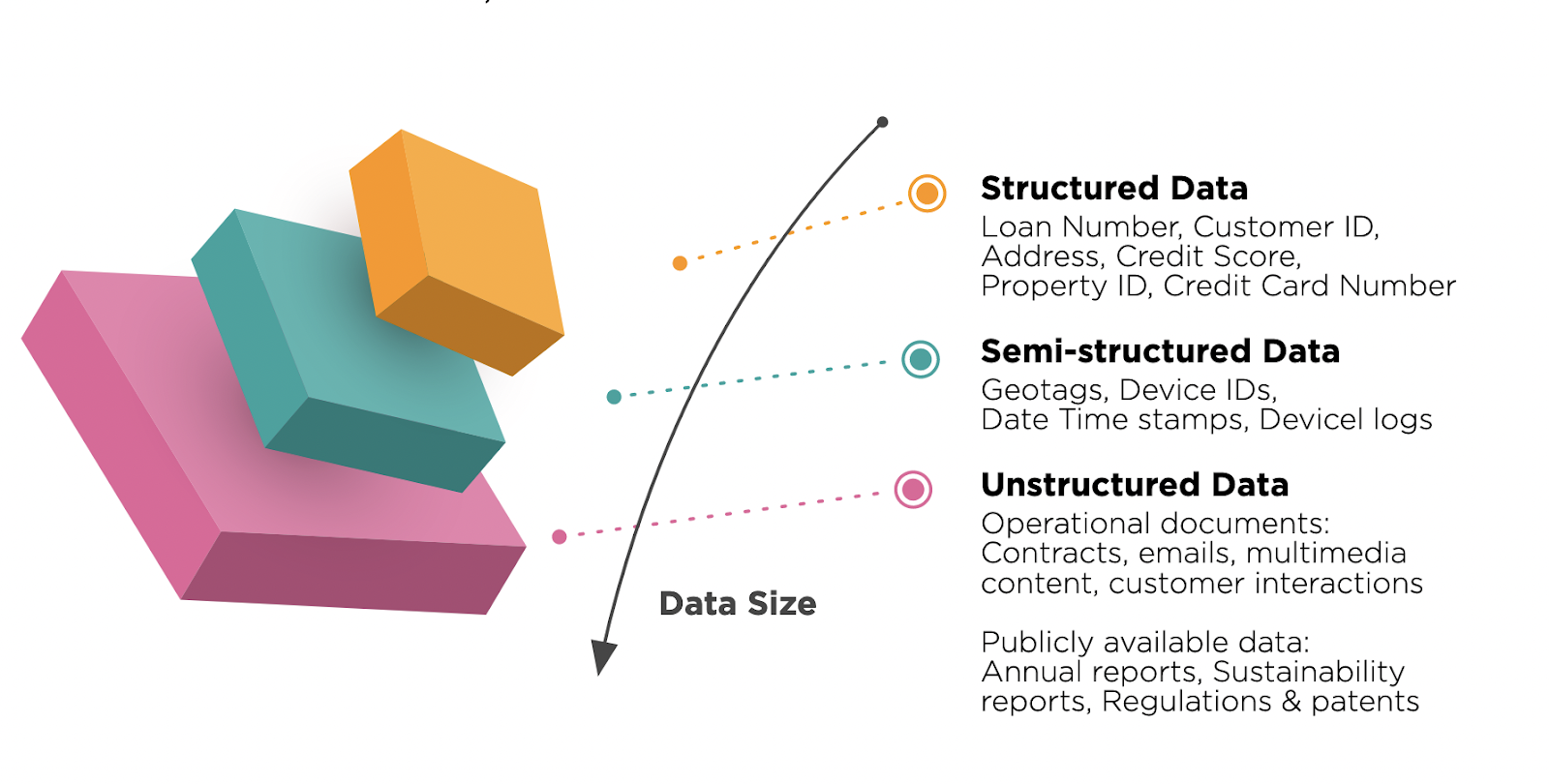
Big data comprises structured, semi-structured, and unstructured data. All these types of data have a lot to offer. Let’s take a look at their differences in detail.
Structured data is another kind of data that follows a particular pattern and is easy to recognize. This form of data is available in RDBMS and has many applications. There is a brief table of descriptions between both structured and unstructured data:
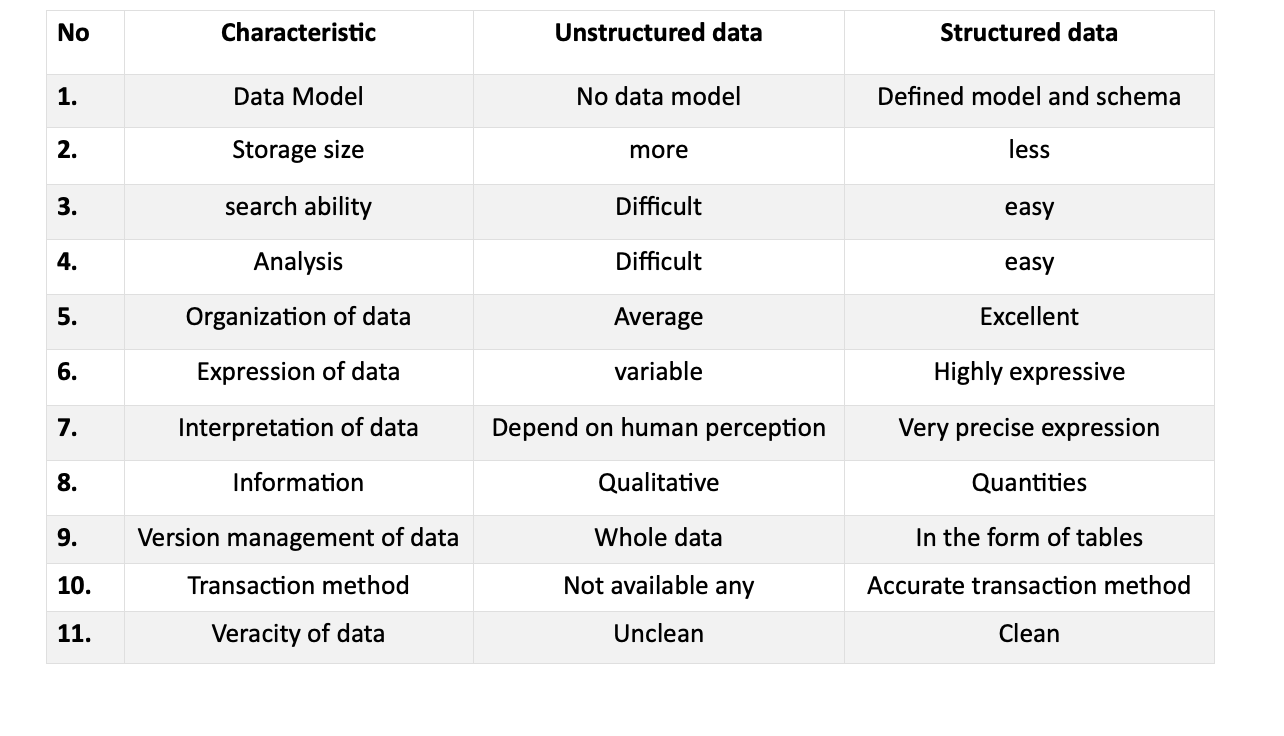
Data Model
- Unstructured data often comes in the form of large pdfs, text, or multimedia files, while structured data is precise and organized.
- The defined model of structured data makes it easy and reliable to study and access.
- Large files require significant storage capacity, making structured data more desirable due to its adjustable file size, often in a tabular format.
Data Analysis
- The analysis determines data relevance and accuracy.
- Unstructured data can contain unreliable or ambiguous knowledge, unlike structured data which is organized and adjusted.
- Structured data is preferred due to the ease of analysis compared to unstructured data.
Searchability
- Unstructured data extraction can be chaotic, making the search for major points time-consuming.
- Structured data is easily searchable due to its organization.
- Unstructured data can be hard to understand and search due to its size and format.
Visionary Analysis
- The focused analysis of unstructured data can reveal valuable insights.
- Data in a short, up-to-date format attracts more interest than lengthy paragraphs.
- Structured data allows for quicker authentication of information, saving users time.
What are the challenges while working with unstructured data?
The unstructured data comes in highly long-form and that’s why unstructured data extraction is necessary. Many challenges are faced by the working staff while working with unstructured data. First of all, this type of data is available in a bulk text of any other form, that’s why it takes too long to do with this data. Second, if the data is available in big files, as most probably unstructured data presents, takes too much storage. The quality of the structured data is that it presents in very precise and tabular forms, that’s why extraction of the data is very easy.
Compromised relevancy
It is seen that unstructured data contains much information that is not valuable and highly inaccurate and irrelevant. The accuracy of the data should be maintained in the best possible way, that’s why the biggest challenge faced with unstructured data extraction is to maintain the quality of relevant and accurate data intact.
Storage
Since the time of digitalization of the World in the 20th century, data success comes with occupying less storage and more information. In past, data was saved in many large files, the unstructured data is taking too much storage that it has now become a challenge to deal with all these changes.
Dealing with unstructured data is high time taking. It took too long to extract information from unstructured data when it comes to the urgency of the data. That’s why, the data took too long and in urgency, it is very difficult to extract all the knowledge from the data.
Since the start of digitalization, many tools have come into being to deal with the challenges of unstructured data extraction. To save time, the unstructured data extraction via AI-enhanced data extraction tools like Nanonets is very reliable because it provides thorough and altogether relevant information for data. The relevancy of the data is very important because it is an important time-saving tool for the working staff and analysts. With these data strategies, one can easily interpret valuable information from the data.
How can you use Nanonets to convert unstructured data into insights?
Nanonets is a platform that employs AI, ML & NLP techniques to help users derive insights from unstructured data. Here’s a simplified step-by-step guide on how to achieve this:
- Data Collection: Gather your unstructured data. This could be in the form of images, text files, PDFs, videos, or audio files.
- Upload to Nanonets: Upload your unstructured data to the Nanonets platform using your account. You can create yours here. This could be done directly or via APIs present in the app.
- Choose or Train a Model: Now, based on the document that you’re uploading, select an OCR model. Nanonets provides pre-trained models for many document types. . Choose a model that fits your data type and objective. If none of the pre-trained models suit your needs, you can train a custom OCR model using your data.
- Apply Model to Data: Once your model is ready, apply it to your documents. The model will extract data from your documents and convert it into structured format like table, excel, csv which is easier to read.
- Review and Adjust: Check the results from the model’s analysis. If they aren’t accurate enough, you can fine-tune the model by using Nanonets’ drag and drop platform until the results meet your needs.
- Extract Insights: Finally, use the structured data to derive insights. You can export the data and perform data analytics to derive insights.
Remember, the specific steps might vary based on the specific type of unstructured data and the insights you want to derive. Nanonets can automate the process with automated workflows, powerful OCR software and no-code user interface.
We’re living in a transformative era where digitalization simplifies business growth and decision-making. Unstructured data extraction has streamlined various processes due to its time-saving and fast operation.
Unstructured data, essentially raw material, is processed to extract valuable information for easy storage. Its tabular form enhances accessibility. Data queries are organized into user-friendly, well-structured forms, devoid of ambiguity, making them easy to read. Among the various data extraction tools available, each contributes to system efficiency and environmental improvement.
Unstructured data extraction is crucial across industries, maintaining data authenticity. For instance, the banking sector utilizes these tools for business growth.
In scientific research, unstructured data extraction tools condense data into a more precise form, irrespective of whether it’s human or machine-generated, providing valuable insights.
Businesses across industries are using unstructured data extraction techniques to make sense of their business documents and add an extra layer of intelligence to their analytics. The figure below shows the advent of the use of unstructured data in different industries.
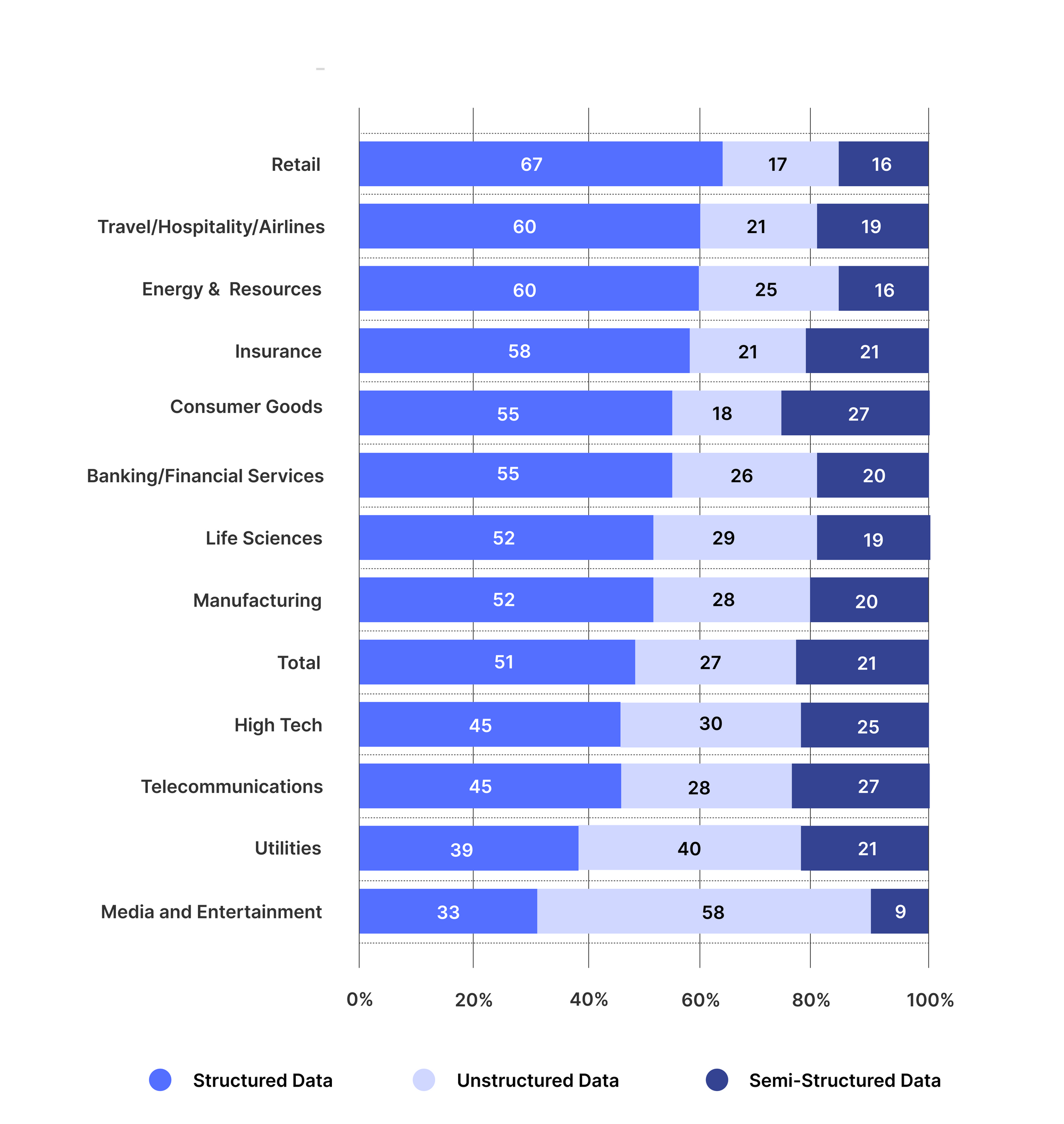
[Source: TCS Study]
Here are some examples of how different industries are using intelligent document processing platforms like Nanonets for unstructured data extraction and enhancing their productivity.
Banks
Banks use IDP platforms to extract insights from unstructured data sources like claims, customer forms, KYC documents, call records, financial reports, and more.
Read more: RPA in Banking and Banking Automation
Insurance
Insurance is a heavily regulated industry. It needs to perform document verification and identity verification at every step of insurance claims processes. Insurance firms use automated document processing platforms to automate claims processes, risk management, and other functions which are rule-based. The insurance claims process contains a lot of unstructured data. Unstructured data extraction by using AI-enhanced platforms like Nanonets makes the insurance claims process easy as it allows for selective data extraction from images, PDFs, videos, audios, etc.
Read more: Insurance Automation, Insurance OCR, and RPA in Insurance
Health
Providing exceptional patient experience revolves around providing better service, reducing patient wait times, and ensuring staff aren’t overworked. Using IDP platform to extract insights from unstructured data sources like the voice of customer data, patient surveys, EHRs, customer complaints, regulatory websites, and literature review helps Healthcare to ensure a better patient experience.
Read more: Healthcare automation and AI in healthcare
Real Estate
Real estate companies deal with multiple people at the same time like customers, builders, tenants, vendors, competitors, and property owners. Using automated document processing software can help real estate institutions to create rich profiles of mentioned stakeholders and streamline the data extraction from unstructured data sources like rent leases, contracts, property valuation papers, etc.
Conclusion
Data is the new oil. The business that masters unstructured data extraction can unlock the full potential of enterprise data. Nanonets allow enterprises to automate their document processing and can smartly extract data from any kind of document.
Nanonets online OCR & OCR API have many interesting use cases that could optimize your business performance, save costs and boost growth. Find out how Nanonets’ use cases can apply to your product.
FAQ
What are advantages of using unstructured data?
Unstructured data is difficult to understand, interpret and use directly, but that’s not the only thing about it. There are many advantages of using unstructured data, as mentioned below:
No Fixed Format
Unstructured data supports data of all formats and sizes. Any kind of data that does not have a proper sequence can be classified as unstructured data. It can be useful to expand the horizon of types of data.
No Schema
As discussed above, unstructured data has no fixed sequence and it also has no fixed schema. This is what makes unstructured data extraction difficult for most of the parts.
Flexibility
Given unstructured data has no structure, it can have any format. This makes it fluid in terms of structure.
Portable & Scalable
Unstructured data is more portable and scalable as compared to semi-structured and structured data.
Lots of Business Applications
Given that 80% of the enterprise, company data is unstructured, there are a lot of applications for this data. Unstructured enterprise data is used for a variety of business analytics use cases. For example, presentations, company videos, understanding customer profiles, etc.
How do convert unstructured data into structured data?
While working with big and bulky data can be a hectic task. To save time and to maintain the originality and accuracy of the data, it should be shortened to such an extent that only necessary information remains left. The unstructured data extraction has different methods and its significance is very much shown by all the information provided above. The difference between the structured and unstructured give important clues about the data. You can use the following steps to convert unstructured data into structured data.
Step 1: Have a Clear Goal in mind
No project should ever start without having a set of measurable goals. With a clear idea of the end goal of what insights you want to obtain, it becomes easier to finalize the next steps.
Step 2: Finalize the data sources
Data is everywhere. But, to start with the conversion, you need to identify the data sources to draw your unstructured data. Data extraction strategies would be different for different data sources. Nanonets allow users to collect data from multiple sources like Gmail, drop box, outlook, desktop, etc.
The data can be extracted from the big pdf files, images, and other text forms.
Step 3: Standardization of Data
The third step is to know what to do with unstructured data extraction. The analyst should have an idea about the final result of the unstructured data.
If you have selected the data, the next step is to finalize the outcome of the data. If the data is in any variable form, the analyst needs to standardize it before any analysis can be performed. This particular step involves cleaning and standardizing the data formats for the next steps.
Step 4: Selecting the data extraction technology:
After understanding the data sources and the method of standardizing the data, it is important to finalize the software that you want to use for implementing these steps. IDP platforms like Nanonets help organizations to connect, extract data and standardize it for further analysis.
The data will be taken by different software, the next step is to find the technology by which the data will be transferred to the software. For this purpose, a rational database management system (RDBMS) is used. This software and technology help to get straightforward technology use.
Step 5: Selecting the data storage system
The data storage system is selected based on the type of technology that you are looking for, it should have high availability, high-velocity time, and other features. All these features along with the real-time storage capacity make the high storage system.
Source: https://nanonets.com/blog/unstructured-data-extraction/
