The Amazon International Seller Growth (ISG) team runs the CSBA (Customer Service by Amazon) program that supports over 200,000 third-party Merchant Fulfilled Network (MFN) sellers. Amazon call centers facilitate hundreds of thousands of phone calls, chats, and emails going between the consumers and Amazon MFN sellers. The large volume of contacts creates a challenge for CSBA to extract key information from the transcripts that helps sellers promptly address customer needs and improve customer experience. Therefore, it’s critical to automatically discover insights from these transcripts, perform theme detection to analyze multiple customer conversations, and automatically present a set of themes that indicate the top reasons for customer contact, so that the customer problems are addressed in the right way and as soon as possible.
This post presents a solution that uses a workflow and AWS AI and machine learning (ML) services to provide actionable insights based on those transcripts. We use multiple AWS AI/ML services, such as Contact Lens for Amazon Connect and Amazon SageMaker, and utilize a combined architecture. This solution is tested with ISG using a small volume of data samples. In this post, we discuss the thought process, building this solution, and the outcome from the test. We believe the lessons learned and our journey presented here may help you on your own journey.
Operational landscape and business workflow
The following figure shows the recommended operational landscape with stakeholders and business workflow for ISG so that sellers can stay close to their customers anytime, anywhere. The consumer contacts Customer Service through a contact center platform and engages with the Customer Service Associate (CSA). Then the transcripts of contacts become available to CSBA to extract actionable insights through millions of customer contacts for the sellers, and the data is stored in the Seller Data Lake. Sellers use the Amazon Seller Central portal to access the analytics outcomes and take action to quickly and effectively address customer problems.
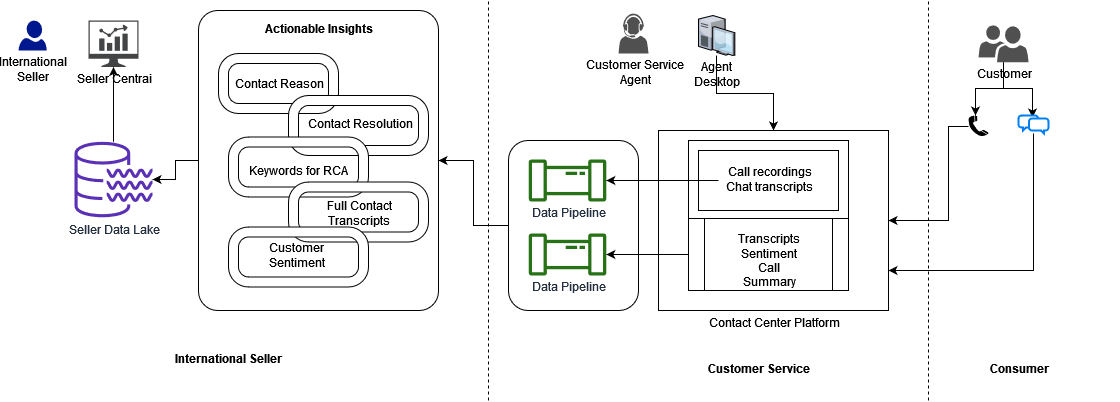
Solution overview
The following diagram shows the architecture reflecting the workflow operations into AI/ML and ETL (extract, transform, and load) services.
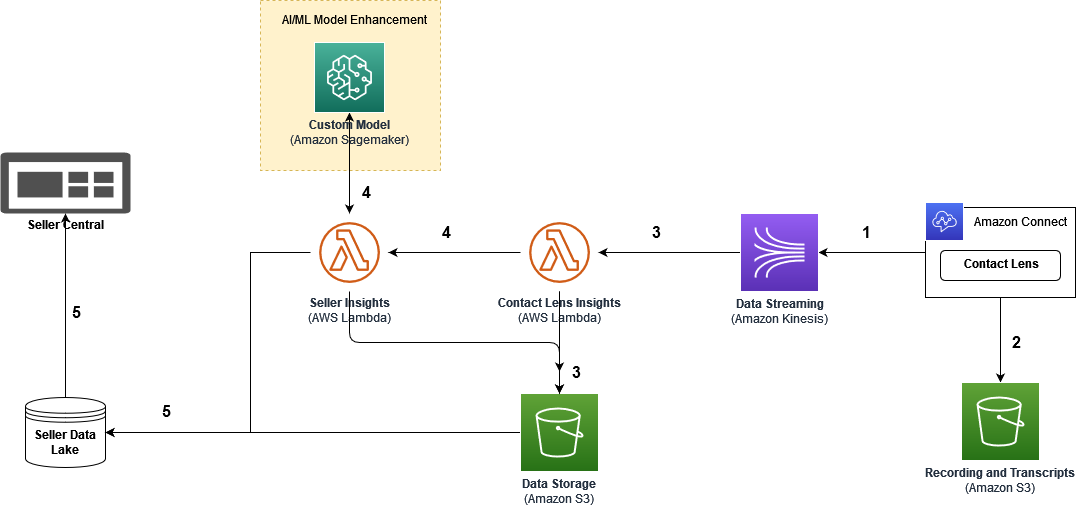
The workflow steps are as follows:
- We use Amazon Connect as a cloud contact center for consumer-CSA interactions. Contact Lens for Amazon Connect generates call and chat transcripts; derives contact summary, analytics, categorization of associate-customer interaction, and issue detection; and measures customer sentiments.
- Contact Lens then stores analytics data into an Amazon Simple Storage Service (Amazon S3) bucket for long-term retention.
- Amazon Kinesis Data Streams collects and transfers the high-throughput analytics data, processed by AWS Lambda, and injects and stores the data into an intermediate S3 bucket. At this stage, the data contains call and chat transcripts, sentiment scores, detected issues, and categories.
- It triggers the Lambda functions to ingest the data stream, extract the requested data fields, and trigger inference of custom ML analyses by AWS AI/ML services, on top of Contact Lens results.In this analysis, Contact Lens provides accurate sentiment scores measuring customer satisfaction on consumer-CSA interactions. Contact Lens rules help us categorize known issues in the contact center. At this stage, ISG wanted to provide additional insights to the seller by detecting the theme through discovering previously unknown issues in seller-specific calls, performed resolutions, and specific key phrases. Here, a non-deep learning model was trained and run on SageMaker, the details of which will be explained in the following section.
- After the AI/ML-based analytics, all actionable insights are generated and then stored in the Seller Data Lake. The insights are shared on the Seller Central Portal for the international sellers to pinpoint the root cause and take prompt action.
In the following sections, we dive deeper into the AI/ML solution and its components.
Data labeling
In this section, we describe our approach for data labeling to identify the contact reason and resolution, and our methodology for keywords extraction for the sellers to perform root cause analysis.
Contact reason and resolution labeling
To detect the contact reason from transcripts by ML, we utilized seven Standardized Issue Codes (SICs) as the data labels from the sample data provided by ISG team:
- Contacted seller to request cancelation
- Tracking shows delivered but shipment not received
- Shipment undeliverable
- Shipment not delivered past delivery date
- Shipment in transit to customer
- Request Return Mailing Label (RML)
- Item non-returnable
The contact reason labels can be further extended by adding the previously unknown issues to the seller; however, those issues had not been defined in the SIC. Unlike the contact reason, the contact resolution doesn’t have a label associated with the transcripts. The resolution categories were specified by the ISG team, and the resolutions needed to be labeled based on these categories. Therefore, we utilized Amazon SageMaker Ground Truth to create or update labels for each contact.
Ground Truth provides a data labeling service that makes it easy to label data, and gives you the option to use human annotators through Amazon Mechanical Turk, third-party vendors, or your own private workforce. For this solution, the ISG team defined for categories for contact resolution in over 140 transcript documents, which were labeled by Amazon Mechanical Turk contractors:
- Full refund – 69 records
- Contact seller – 52 records
- Partial refund – 15 records
- Other – 4 records
It only took a couple of hours for the contractors to complete the multi-label text classification contact center resolution labeling for the 140 documents, and have them reviewed by the customer. In the next step, we build the multi-class classification models, then predict the contact reason and resolution from the new call and chat transcripts coming from the customer service.
Keywords for the root cause analysis
Another challenge is to extract the keywords from the transcripts that can guide the MFN sellers on specific actions. For this example, the seller needs to capture the key information such as product information, critical timeline, problem details, and refund offered by the CSA, which may not be clear. Here we built a custom key phrases extraction model in SageMaker using the RAKE (Rapid Automatic Keyword Extraction) algorithm, following the process shown in the following figure. RAKE is a domain-independent keyword extraction algorithm that determines key phrases by analyzing the frequency of word appearance and its co-occurrence with other words in the text.
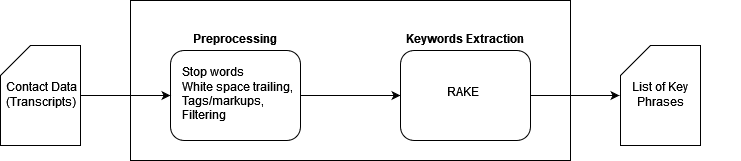
After the standard document preprocessing, RAKE detects the most relevant key words and phrases from the transcript documents. The output is listed as follows:
This method captured key phrases with high relevance scores on the critical information such as timeline (“June 23”), refund resolution (“Amazon gift card,” “in 5 business days”), product information (“charcoal combo grill,” “dual fuel gas,” “gbc1793w”) and problem details (“faulty piece,” “bent pieces”). These insights not only tell the seller that this customer has been taken care of by getting a refund, but also guide the seller to further investigate the gas grill product defect and avoid having similar issues for other customers.
Text classification model training
Contact Lens generated transcripts, contact summary, and sentiments for call and chat samples collected from ISG Customer Service. Throughout the testing, the transcription and sentiment scores were accurate as expected. Along with known issues, the ISG team also looks for detecting unknown issues from transcripts to meet the seller-specific needs such as delivery problems, product defects, the resolutions provided by the contact, and issues or key phrases leading to a return or refund.
To address this challenge, we extended our tests through custom models on SageMaker. Our experience pointed to “bag-of-words” based, more conventional (non-deep learning) models using SageMaker based on the size of the dataset and samples.
We performed the contact reason classification modeling following the three steps on SageMaker as shown in the following figure.

The steps are as follows:
- Preprocessing – We used the NLTK library to lower the cases; remove punctuation, tags, markups, and white space trailing; and filter single letters, numeric values, and customized lists of stop words.
- Vectorization – We used the TF-IDF (Term Frequency-Inverse Document Frequency) method to convert the processed document into a matrix of TF-IDF features. The method quantifies the importance and relevance of words and phrases in a document with a collection of documents (corpus), then generates the features in numeric values to represent how important a word is to the document in the corpus. For this solution, we tested with specifying 750 and 1,500 features.
- Multi-class classification – We generated a seven-class classification model using a vectorized feature list and SIC labels. We utilized 90% of the samples for training and 10% for validation.
We tested three algorithms aiming to obtain the best-performing model:
- First, we used the SageMaker Linear Learner algorithm with default hyperparameters and performed 10 epochs, and reached 71% accuracy for the testing set.
- Next, we used the SageMaker built-in XGBoost algorithm, and ran automatic hyperparameter optimization (HPO) tuning on four parameters (eta, alpha, min_child_weight, max_depth), which gave us 71% accuracy for the testing set.
- Finally, we worked with AutoGluon’s AutoML framework on SageMaker, which performs automatic modeling and hyperparameter selection with multiple models ensembling and multiple layers stacking. The framework trained 13 models and generated the final ensemble model yielding 74% accuracy for the testing set. We also tested by increasing the number of TF-IDF vectorizer features to 1,500; with the AutoGluon model, the classification accuracy on testing set can be further improved to 82%.
For our model training through AutoGluon, we used the MultilabelPredictor method from the AutoGluon library. This predictor performs multi-label prediction for tabular data. We used the sample notebook from AWS samples on GitHub. We used the same notebook by starting with importing AutoGluon libraries and defining the class for MultilabelPredictor(). To save space, we don’t show those lines in the following code snippet; you can copy/paste that part from the sample notebook. We employed the training in the file train.csv in our S3 bucket (your_path_to_s3/train.csv), specified the column used for label, and performed model training through MultilabelPredictor.
The following table lists the AI/ML services and models, and summarizes the accuracy.
| . | Transcripts | Feature | Linear Learner | XGB with HPO | AutoGluon |
| Validation set | 11 | 750 | 0.91 | 0.82 | 0.82 |
| Validation set | 11 | 1500 | 0.82 | 0.82 | 0.91 |
| Testing set | 34 | 750 | 0.71 | 0.71 | 0.74 |
| Testing set | 34 | 1500 | 0.65 | 0.65 | 0.82 |
The following charts summarize the accuracy for the sample set based on amount of features.
 |
 |
In the following charts, we observed that the models of the decision tree with a gradient boosting machine, such as LGB, XGBoost, and Random Forest, were better choices for this type of problem for both the 750-feature models and 1,500-feature models. The neural net model is ranked lower among the 13 models, which confirmed our expectation that deep learning might not be suitable for our case.
 |
 |
Conclusion
With AWS AI/ML services, we can provide accurate and efficient contact reason and contact resolution detection and other actionable insights for Amazon International Seller Growth. MFN sellers can use these insights to better understand consumer problems, and take effective actions to resolve Amazon consumers’ issues, while also optimizing their process and costs.
You can tailor the solution for your contact center by developing your own custom model in SageMaker, and feeding the call and chat transcripts for training and inference. You could also apply this solution for general theme detection to analyze customer conversations in your contact center.
About the Authors
 Yunfei Bai is a Senior Solutions Architect at AWS. With the background in AI/ML, Data Science and Analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and Data Analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei is a PhD in Electronic and Electrical Engineering . Outside of work, Yunfei enjoys reading and music.
Yunfei Bai is a Senior Solutions Architect at AWS. With the background in AI/ML, Data Science and Analytics, Yunfei helps customers adopt AWS services to deliver business results. He designs AI/ML and Data Analytics solutions that overcome complex technical challenges and drive strategic objectives. Yunfei is a PhD in Electronic and Electrical Engineering . Outside of work, Yunfei enjoys reading and music.
 Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has +15 years of industry experience in simulation modeling, data science and ML technology. He helps global customers adopting AWS technologies and especially, AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Eng. from METU, MS in Systems Engineering and post-doc on system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
Burak Gozluklu is a Principal ML Specialist Solutions Architect located in Boston, MA. Burak has +15 years of industry experience in simulation modeling, data science and ML technology. He helps global customers adopting AWS technologies and especially, AI/ML solutions to achieve their business objectives. Burak has a PhD in Aerospace Eng. from METU, MS in Systems Engineering and post-doc on system dynamics from MIT in Cambridge, MA. Burak is passionate about yoga and meditation.
 Chelsea Cai is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where she works for Customer Service by Amazon service (CSBA) helping 3P sellers improve their customer service/CX through Amazon CS technology and worldwide organizations. In her spare time, she likes philosophy, psychology, swimming, hiking, good food, and spending time with her family and friends.
Chelsea Cai is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where she works for Customer Service by Amazon service (CSBA) helping 3P sellers improve their customer service/CX through Amazon CS technology and worldwide organizations. In her spare time, she likes philosophy, psychology, swimming, hiking, good food, and spending time with her family and friends.
 Abhishek Kumar is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where he develops software platforms and applications to help global 3P sellers manage their Amazon business. In his free time, Abhishek enjoys traveling, learning Italian, and exploring European cultures and cuisines with his extended Italian family.
Abhishek Kumar is a Senior Product Manager at Amazon’s International Seller Growth (ISG) organization, where he develops software platforms and applications to help global 3P sellers manage their Amazon business. In his free time, Abhishek enjoys traveling, learning Italian, and exploring European cultures and cuisines with his extended Italian family.
